Ingestion pipelines
Batch vs streaming ingestion, idempotency, backfills, and reliable processing.
An ingestion pipeline takes content from your sources and transforms it into the indexed, searchable form your retrieval system uses. Getting this pipeline right is the difference between a knowledge base that stays current and one that slowly drifts out of sync with reality.
The pipeline shape
At a high level, every ingestion pipeline follows the same pattern. You fetch content from a source, extract text from whatever format it's in, clean and normalize that text, chunk it into retrieval units, generate embeddings for those chunks, and store everything in your index.
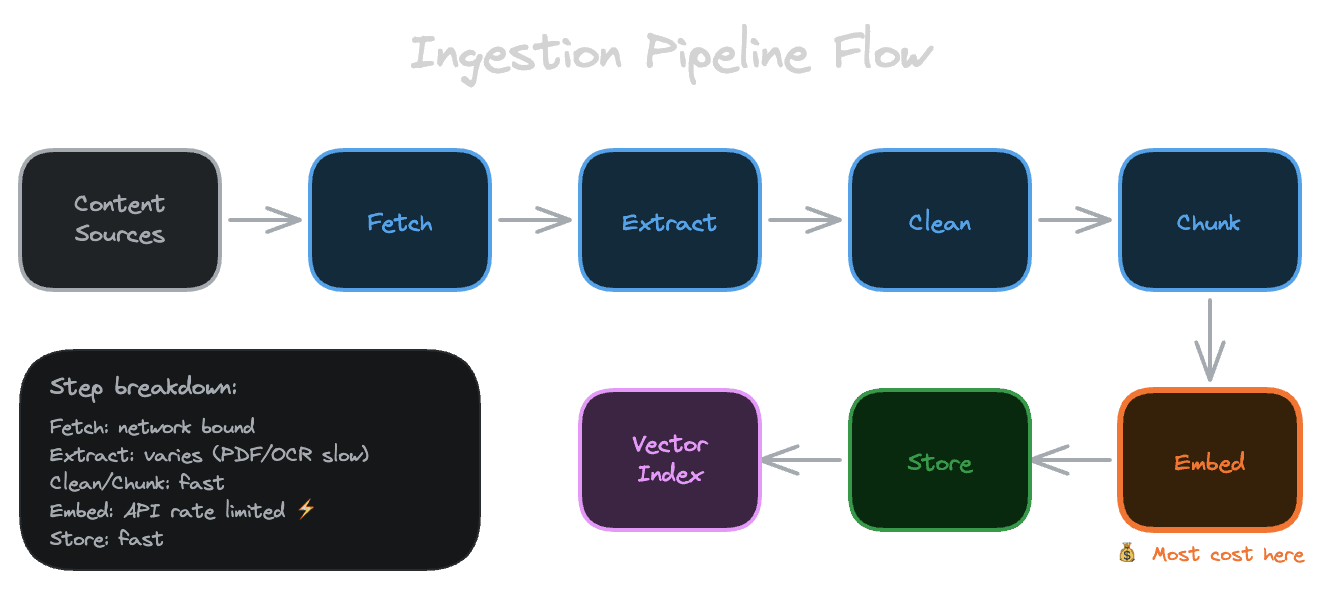
Each step can fail independently, and the pipeline needs to handle those failures gracefully. The source might be temporarily unavailable. Extraction might fail on a malformed document. The embedding API might rate-limit you. Your database might reject a write. A robust pipeline anticipates these failures and either retries or records the failure for later investigation.
Batch versus streaming
There are two fundamental approaches to running ingestion.
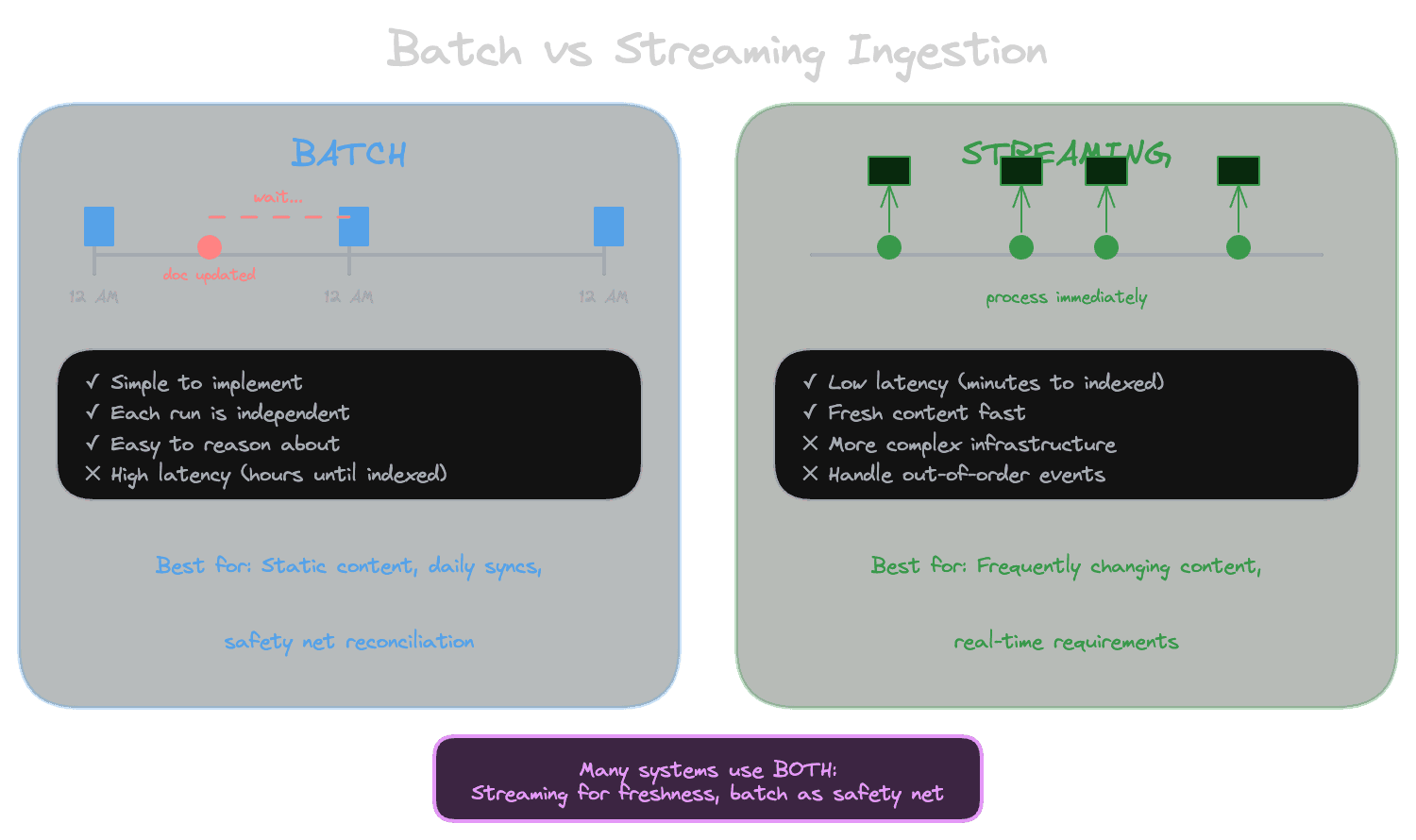
Batch ingestion processes content in scheduled runs. You might run a full sync every night, or process a queue of changed documents every hour.
Advantages:
- Simpler to implement: write a script that fetches everything, processes it, and updates the index
- Easier to reason about because each run is independent
- Better for full reprocessing and backfills
Disadvantages:
- Higher latency: if your batch runs nightly, a document updated at 8 AM won't be searchable until the next morning
- Not suitable for content that changes frequently
With Unrag: Run a script that calls engine.ingest() on a schedule. See admin reingest example for patterns.
Streaming ingestion processes content as it changes. When a document is created or updated, an event triggers processing immediately (or within minutes).
Advantages:
- Better freshness: changes are searchable within minutes
- Lower total resource usage (only process what changed)
Disadvantages:
- More complex: need event infrastructure, handle out-of-order events
- Different failure modes (partial failures, retries)
Recommended approach: Many production systems use both. Streaming handles incremental updates for low latency. Periodic batch runs serve as a safety net, catching anything the streaming pipeline missed.
Idempotency is non-negotiable
An idempotent operation produces the same result whether you run it once or multiple times. For ingestion, this means processing the same document twice should leave your index in the same state as processing it once.
Without idempotency, you get duplicates. Run the pipeline twice, and every document appears twice in your index. Retry a failed batch, and the documents that succeeded the first time now have duplicates. Users see the same content repeated in results, or worse, conflicting versions of the same information.
Idempotency requires stable identifiers. Each chunk needs an ID that's derived from its content and position, not randomly generated. When you process a document, you update existing chunks rather than creating new ones.
With Unrag: Use consistent sourceId values when calling engine.ingest(). The same sourceId replaces existing content rather than duplicating it. See document modeling for best practices.
Handling changes correctly
Content doesn't just get created; it gets updated and deleted. Your pipeline needs to handle all three.
Creates are straightforward: generate chunks, embed them, store them.
Updates are trickier. When a document changes, its chunks might change too—different text, different boundaries, different count. The safest approach is "replace" semantics: delete all existing chunks from this document, then insert the new ones. This ensures you don't have stale chunks lingering from a previous version.
Deletes are often forgotten. When a document is removed from the source, its chunks should be removed from the index. Otherwise, your system continues to return content that no longer exists, leading to broken links and user confusion. Implementing deletes requires tracking which chunks came from which source documents—another reason stable identifiers matter.
Retries and error handling
Network calls fail. APIs rate-limit. Databases have transient errors. Your pipeline needs a retry strategy.
For transient errors (network timeouts, rate limits, temporary unavailability), retry with exponential backoff. Start with a short delay, increase it with each retry, and cap the maximum delay. This prevents hammering a struggling service while eventually completing the work.
For permanent errors (malformed documents, unsupported formats, validation failures), don't retry forever. Log the error, skip the document, and move on. Retrying a document that can't be processed just wastes time and obscures the real problem.
Consider whether to use a queue. Placing documents in a queue before processing decouples fetching from processing. If processing fails, the document stays in the queue for retry. This makes the pipeline more resilient but adds operational complexity.
Backfills and full reprocessing
Sometimes you need to reprocess everything. Maybe you changed your chunking strategy. Maybe you switched embedding models. Maybe you discovered a bug that affected all documents processed in the last month.
Design your pipeline to support full reprocessing from the start. This means you can fetch all content from a source (not just changes since last run), and your idempotent processing can update the index without creating duplicates.
Full reprocessing should be a button you can push, not an emergency surgery. Test it periodically so you know it works when you need it.
Backpressure and resource limits
Ingestion competes for resources with retrieval. If your pipeline is embedding thousands of documents while users are trying to search, both might suffer. Worse, you might exhaust API rate limits or database connections, causing failures in the user-facing system.
Build backpressure into your pipeline. Limit concurrent operations. Respect rate limits with proper throttling. Consider running heavy ingestion during off-peak hours. Monitor resource usage and pause processing if the system is under stress.
The goal is sustainable throughput: processing content as fast as you can without impacting retrieval quality or reliability.
Next
With pipelines moving content through the system, the next chapter addresses what happens to that content along the way: cleaning and normalization.