Parent/child and hierarchical retrieval
Retrieve small units for precision, then expand to larger context for usefulness.
The tension between chunk size and context is real: small chunks give precise retrieval but lack context; large chunks provide context but sacrifice precision. Parent-child chunking offers a way to have both. You retrieve at one level of granularity for precision, then expand to a larger unit for context before passing to the LLM.
The core pattern
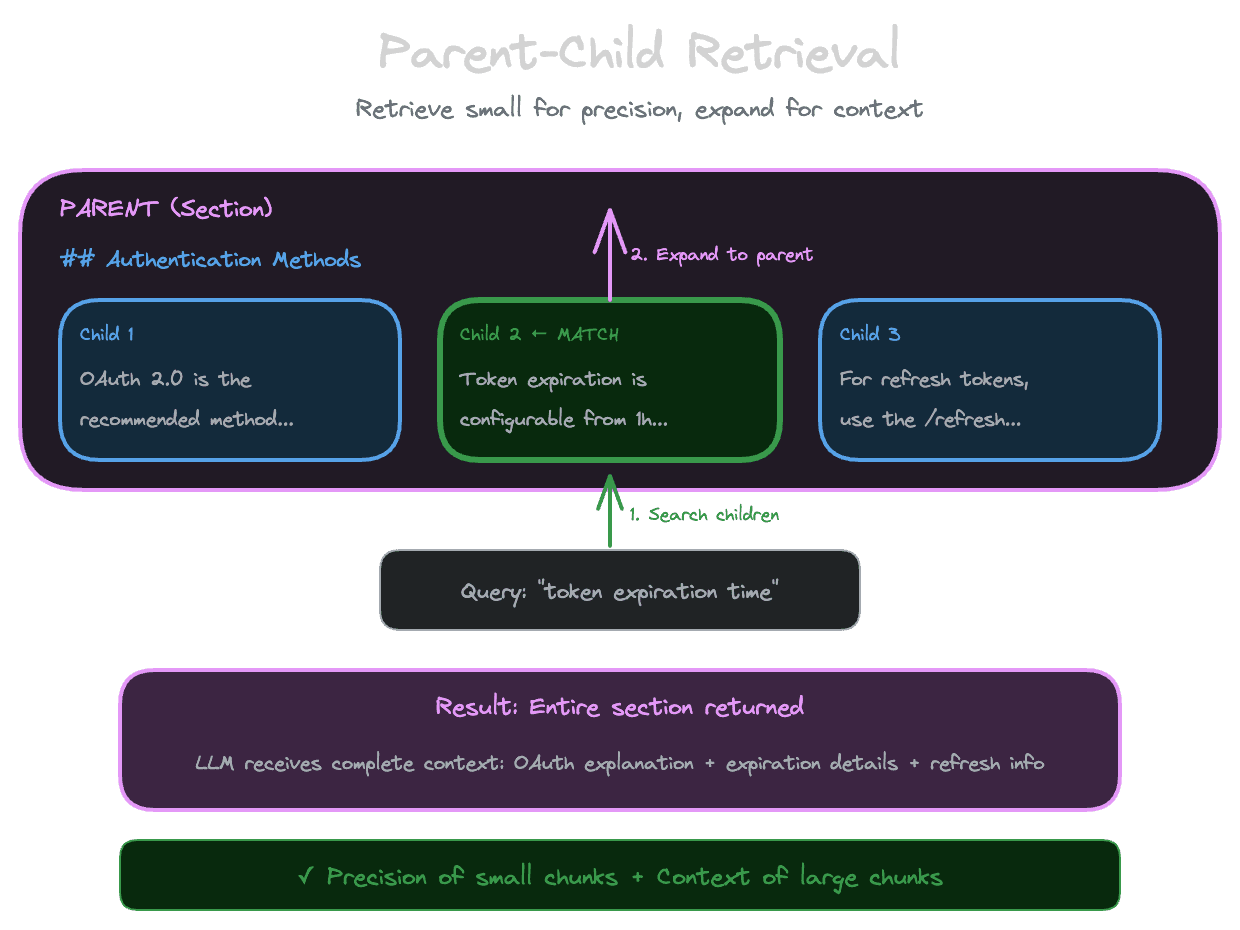
The idea is simple. Create chunks at two (or more) levels of granularity and link them. A "parent" chunk might be an entire section; "child" chunks are the paragraphs within it. At retrieval time, you search the children (for precision) but return or expand to the parents (for context).
When a query matches a specific paragraph (the child), you don't just return that paragraph—you return the entire section (the parent) so the LLM has surrounding context to understand and use the information.
This gives you the best of both worlds: the search operates at high precision on small units, but the LLM receives larger, more complete context.
Building the hierarchy
At ingestion time, you create both levels of chunks and establish the relationships.
Parent chunks are larger units—sections, pages, or documents. Each gets embedded, but they're also stored as the context that children expand to.
Child chunks are smaller units—paragraphs, sentences, or subsections. Each gets embedded and includes metadata pointing to its parent.
When you retrieve a child, you look up its parent and either return the parent directly or include additional context from the parent in the result.
The relationship is typically stored as metadata on the child: "parent_id: section_123". At retrieval time, you fetch the parent content by ID.
Retrieval strategies
There are several ways to use the parent-child relationship at retrieval time.
Replace with parent. When a child matches, return the parent instead. This ensures complete context at the cost of potentially including irrelevant content from other children in the same parent.
Expand to parent. When a child matches, return both the child and its parent. The LLM sees the specific match and the broader context. This uses more context window but provides explicit signal about what specifically matched.
Merge children under parents. If multiple children from the same parent match, deduplicate and return the parent once. This prevents redundant context when several parts of a section are relevant.
Retrieve at both levels. Search both parent and child embeddings. High-level queries might match parents directly; specific queries match children. Merge results, preferring child matches when available and falling back to parents otherwise.
The right strategy depends on your typical query patterns and how much context your LLM needs.
Section expansion as a simpler alternative
A lighter-weight approach than full parent-child indexing is section expansion at retrieval time. You chunk normally, but when returning results, you expand each chunk to include surrounding context.
For example, if you retrieve a chunk that's lines 100-120 of a document, you might expand it to lines 90-130 to capture context that came before and after. This doesn't require a second set of embeddings, just the ability to fetch surrounding content at retrieval time.
The expansion can be based on character count, line count, or structural boundaries (expand to include the enclosing section). This is simpler to implement than maintaining separate parent embeddings, but less precise—the expansion is arbitrary rather than semantically meaningful.
Storage and performance considerations
Parent-child indexing increases storage and complexity. You're embedding more content (both levels of granularity) and maintaining relationships between chunks.
The performance impact at retrieval time depends on your strategy. If you retrieve children and look up parents, you add a database lookup per result. If you retrieve at both levels and merge, you're searching a larger index.
For most applications, these overheads are manageable. The retrieval quality improvements often justify the cost, especially for content where context is essential to usefulness.
When hierarchy beats overlap
Overlap is the simpler solution to boundary problems: by repeating content between adjacent chunks, you ensure information at boundaries appears in multiple chunks.
Hierarchy is more powerful because it addresses context, not just boundaries. A parent-child system gives the LLM the entire section, not just the overlapping parts of adjacent chunks. For content where complete context is essential—tutorials with step-by-step progressions, explanations that build on earlier points, code that references earlier definitions—hierarchy provides what overlap can't.
Overlap is sufficient when chunks are relatively independent and context is local. Hierarchy is worth the complexity when chunks are parts of a coherent larger whole.
Next
With chunking strategies covered, the final chapter provides a practical playbook for debugging chunking problems when retrieval isn't working as expected.