Cross-encoder rerankers
Rerank candidates by scoring query+passage jointly for better relevance decisions.
Cross-encoders are the workhorse of reranking. Unlike embedding models that encode query and document separately, cross-encoders process them together, allowing the model to directly compare and reason about the relationship between them. This joint encoding produces more accurate relevance scores at the cost of higher latency.
How cross-encoders differ from embeddings
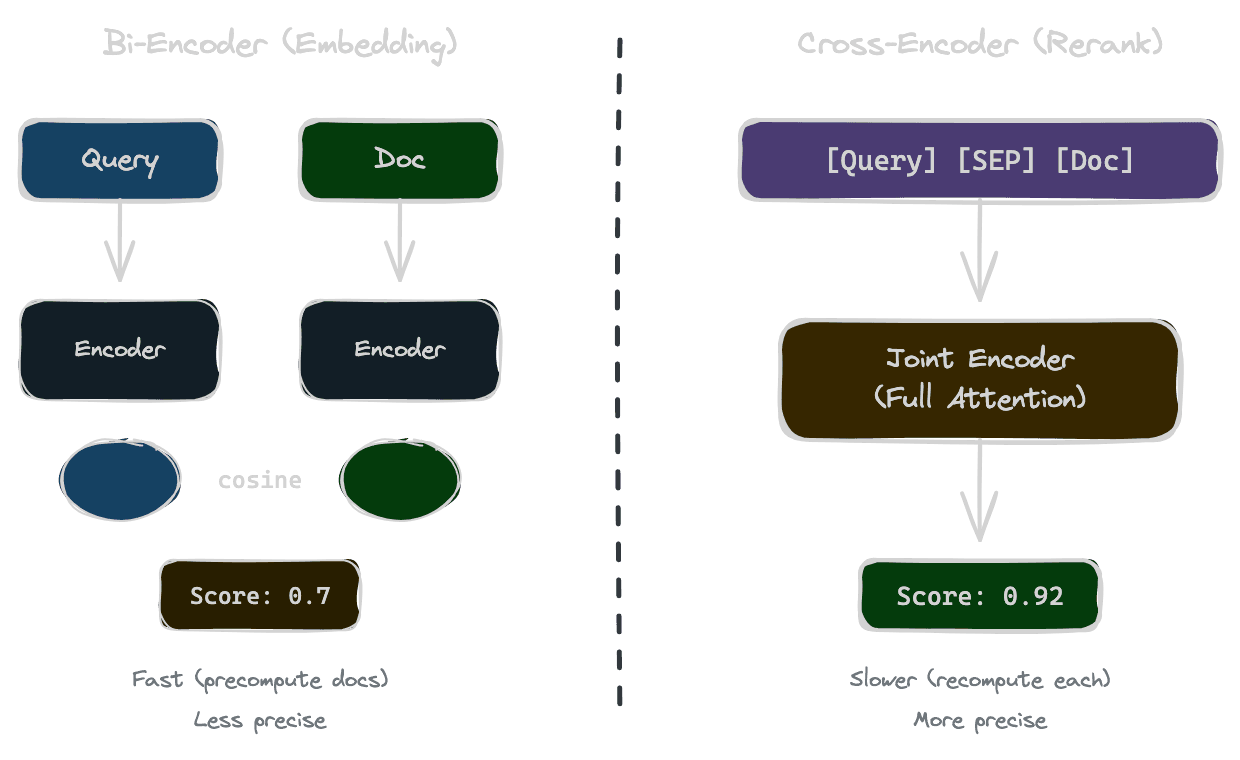
Embedding models (bi-encoders) process query and document independently, producing separate vectors that are then compared using cosine similarity or dot product. This is fast—you can precompute document embeddings—but it limits how much the model can reason about the query-document relationship. The comparison happens in the vector space, not in the model itself.
Cross-encoders take a different approach. They concatenate query and document into a single input: "[query] [SEP] [document]". The model then processes this combined text, with full attention between query and document tokens, and outputs a relevance score. The model can directly "see" both pieces of text together and reason about their relationship.
This joint processing is why cross-encoders produce better relevance judgments. When the model can attend from query tokens to document tokens and vice versa, it can identify whether the document actually answers the question, not just whether they're topically similar.
The tradeoff is speed. You can't precompute anything—every query-document pair requires a fresh forward pass through the model. This is why cross-encoders are used for reranking a small candidate set rather than searching an entire corpus.
Latency and cost implications
A typical cross-encoder takes 20-50ms per query-document pair on a GPU, or 100-200ms on CPU. If you're reranking 50 candidates, that's 1-2.5 seconds on GPU, which is too slow for interactive applications.
Batching is essential. Score all candidates in a single batch to parallelize computation. With batching, reranking 50 candidates might take 100-300ms total rather than 50x individual latency.
Model size matters significantly. Smaller models (like MiniLM-based rerankers) are faster than larger models (like larger transformer-based rerankers). The quality difference is often modest, especially for straightforward relevance judgments. Start with a smaller, faster model and upgrade only if quality is insufficient.
GPU availability changes the equation. Cross-encoders on CPU are slow enough to be impractical for production interactive use. If you can't deploy on GPU, consider LLM-based reranking via API (where the provider handles GPU infrastructure) or accept the latency for batch/offline use cases.
Popular cross-encoder options
Several pre-trained cross-encoders are available for reranking.
The MS MARCO fine-tuned models are trained on a large-scale passage ranking dataset. Models like cross-encoder/ms-marco-MiniLM-L-6-v2 offer a good balance of speed and quality. Larger variants like ms-marco-MiniLM-L-12 provide better quality at higher latency.
Cohere's Rerank API provides a hosted cross-encoder service, eliminating the need to manage model infrastructure. It supports multiple languages and is optimized for production use.
BGE rerankers from BAAI offer strong performance, particularly for multilingual use cases.
For domain-specific applications, you may need to fine-tune a cross-encoder on your own relevance judgments. This requires labeled data (query, document, relevance label triples) but can significantly improve quality for specialized domains.
Where to run reranking
Reranking should happen server-side, after retrieval and before context packing. Never send candidates to the client for reranking—this exposes potentially sensitive content and wastes bandwidth.
The typical flow is: user query arrives at server, server retrieves candidates from vector store, server reranks candidates, server packs top results into context, server sends context to LLM for generation, and finally response returns to user.
For multi-tenant systems, reranking happens after access control filtering. Don't rerank content the user can't see—you'd be wasting compute and potentially leaking information through timing side-channels.
Caching reranked results
Caching reranking results is tricky because the cache key must include both the query and the candidate set. If the underlying content changes, cached scores become stale.
For queries that repeat frequently with the same candidates, caching can help. The cache key should be a hash of the normalized query plus hashes of the candidate IDs and versions.
Invalidation is important: when documents update, invalidate cache entries that include those documents. This can be complex to track, so many applications skip result caching and just rerank fresh each time. The latency impact is usually acceptable.
Query embedding caching is simpler and often more valuable than result caching for reranking, since embeddings can be reused for the retrieval stage.
Evaluating reranker quality
Measure whether reranking actually improves your results. The metrics that matter are precision and recall at the final cutoff.
Compare these scenarios: taking top-5 from vector search directly, versus taking top-5 after reranking top-50 from vector search. If reranking significantly improves precision (correct answers rank higher), it's worth the latency. If results are similar, you might not need reranking.
Use your evaluation dataset to measure. For each test query, check whether the relevant documents appear in the final top-K. Reranking should increase this hit rate compared to vector search alone.
Also measure latency end-to-end. If reranking adds 200ms but improves precision by 30%, that's usually worthwhile. If it adds 500ms for a 5% improvement, reconsider.
Next
Cross-encoders are efficient for pure relevance scoring. The next chapter covers LLM-based reranking—using language models when you need richer criteria or don't have a cross-encoder available.