Two-stage retrieval
Separate fast candidate generation from expensive relevance judgments.
Vector similarity search is fast but imprecise. It computes a rough approximation of relevance by comparing embeddings, but embeddings compress text into fixed-size vectors, losing nuance in the process. Two-stage retrieval addresses this by separating concerns: use fast vector search to generate a candidate set, then apply a more sophisticated model to rerank those candidates by true relevance.
This architecture—retrieve many, rerank few—is how production RAG systems achieve both speed and quality.
Why vector similarity is a coarse filter
When you embed a query and compare it to embedded documents, you're measuring distance in a learned vector space. This works remarkably well for finding topically relevant content, but it has fundamental limitations.
Embeddings are trained to capture semantic similarity in general. They don't know what specifically matters for your query. A query like "What are the refund eligibility requirements?" and a chunk discussing "Our refund process is customer-friendly" might have high similarity because they're both about refunds. But the chunk doesn't actually answer the question about eligibility requirements.
Vector similarity also struggles with nuance. Two chunks might discuss the same topic but one actually answers the question while the other provides tangential background. Their embeddings might be nearly identical, but their utility for answering the query is very different.
Treating vector search as the final word on relevance means you'll often include chunks that are topically related but not actually useful, while potentially missing chunks that are less obviously related but more directly answer the question.
The two-stage architecture
Two-stage retrieval splits the problem into what each stage does best.
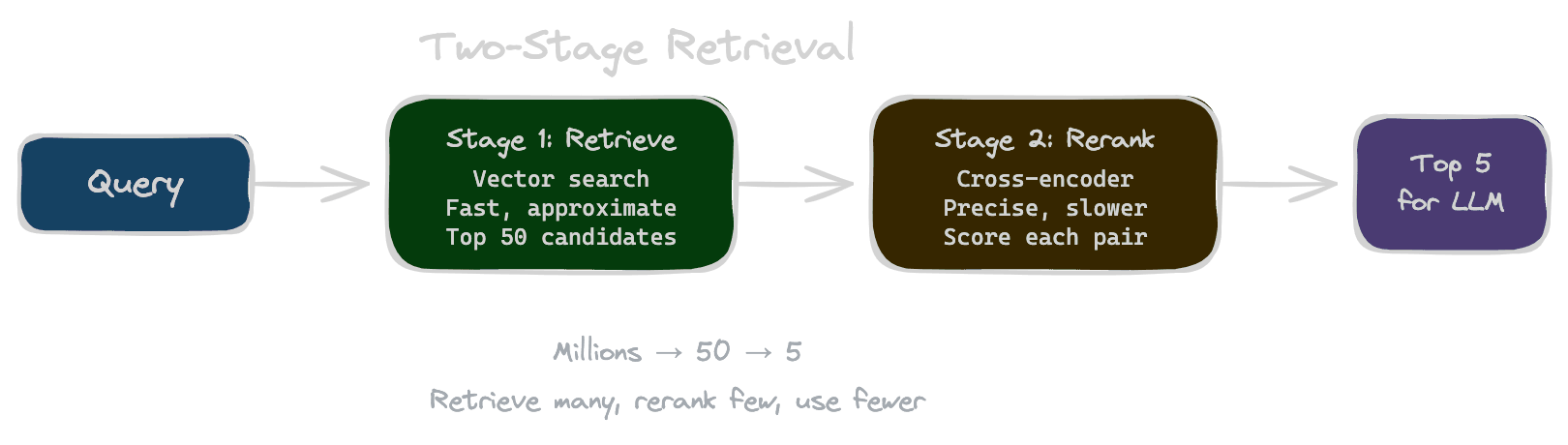
Stage 1: Fast candidate generation
Vector search retrieves a larger set of candidates—typically 20 to 100 chunks—that are approximately relevant. This stage prioritizes recall: you want to make sure the truly relevant chunks are somewhere in this set. Speed matters here because you're scanning potentially millions of vectors.
With Unrag: Use engine.retrieve() with a higher topK value to retrieve candidates. See ANN search.
Stage 2: Precise reranking
A more expensive model scores each candidate against the query to assess true relevance. This stage prioritizes precision: you want to identify which of the candidates are actually useful. Speed matters less because you're only scoring a small set.
With Unrag: Use the built-in reranker powered by Cohere's rerank API, or implement custom reranking.
Final selection
Take the top results—typically 3 to 10—for inclusion in the LLM context. These are the chunks most likely to help answer the query.
Candidate set sizing
How many candidates should the first stage retrieve? Too few and you might miss relevant content; too many and reranking becomes slow and expensive.
The answer depends on the recall characteristics of your vector search. If your embeddings and chunking are well-tuned, relevant content usually appears in the top 20 results. If you're dealing with a harder domain or noisier data, you might need 50 or more candidates to reliably capture what you need.
A practical approach is to measure. Run your evaluation queries, retrieve various candidate set sizes (10, 20, 50, 100), and check whether the truly relevant chunks appear in each set. If relevant content consistently appears in the top 20, there's no benefit to retrieving 100. If you're missing relevant content at 20 but catching it at 50, expand your candidate set.
For the final context, most applications use 3 to 10 chunks. More context isn't always better—it dilutes the relevant information and costs more tokens. The goal of reranking is to identify the best 3-10 from a larger candidate pool.
Where reranking helps most
Reranking provides the biggest improvements in specific scenarios.
When queries are ambiguous, vector search returns topically relevant results that may not address the specific intent. Reranking with a model that jointly considers query and passage can distinguish between "about the topic" and "answers the question."
When your corpus has similar content scattered across many documents, vector search returns many near-duplicates at similar scores. Reranking can identify which specific chunk is most directly relevant.
When you're working with domain-specific content where general-purpose embeddings may not capture the important distinctions, reranking with a tuned model can apply domain-appropriate relevance judgments.
When precision matters more than recall—when wrong answers are worse than no answers—reranking provides an additional quality filter that reduces false positives.
Where reranking helps less
Reranking adds latency and cost. In some scenarios the benefit doesn't justify the overhead.
If your vector search already has high precision—the top 5 results are consistently the right ones—reranking won't improve quality much. Test before assuming you need it.
For simple factual lookups where the answer is either present or not, and topical relevance is sufficient, reranking may be overkill. If users search for "product X pricing" and you have exactly one document about product X pricing, vector search will find it.
When latency is critical and you can't afford any additional processing time, you might need to skip reranking or use a very fast reranker. Measure whether the quality improvement justifies the latency cost for your use case.
Implementing two-stage retrieval
The implementation pattern is straightforward. First, retrieve candidates from your vector store with a higher topK than you'll ultimately use. Then, pass query and candidates to your reranker. Finally, take the top results after reranking for context.
The reranker can be a cross-encoder model, an LLM, or a custom scoring function. The next two chapters cover cross-encoder and LLM reranking in detail.
Keep the original retrieval scores if they're useful for debugging or fallback logic, but use the reranker scores for final ordering.
Next
With two-stage architecture established, the next chapter covers the most common reranking approach: cross-encoder models that jointly score query-passage pairs.