Unrag Documentation
Install small, auditable RAG primitives into your codebase as vendored source files you own and control.
Unrag takes a different approach to building retrieval-augmented generation systems. Instead of shipping a framework or SDK that abstracts away the internals, Unrag installs a small, readable module directly into your codebase. You run one command, and you get TypeScript source files that you own, can read, can modify, and can ship with your application.
The core idea is simple: RAG is not complicated enough to warrant a black-box dependency. The two fundamental operations—ingesting content into vectors and retrieving relevant chunks—can be expressed in a few hundred lines of clear, typed code. Unrag gives you exactly that, wired up to work with Postgres and pgvector out of the box.
When you run bunx unrag@latest init, you get a complete working system:
bunx unrag@latest init --yes --store drizzle --dir lib/unrag --alias @unragThis creates a unrag.config.ts file at your project root (your single place to configure database clients, embedding providers, and defaults) plus a lib/unrag/ directory containing the actual implementation code. From there, using Unrag is straightforward:
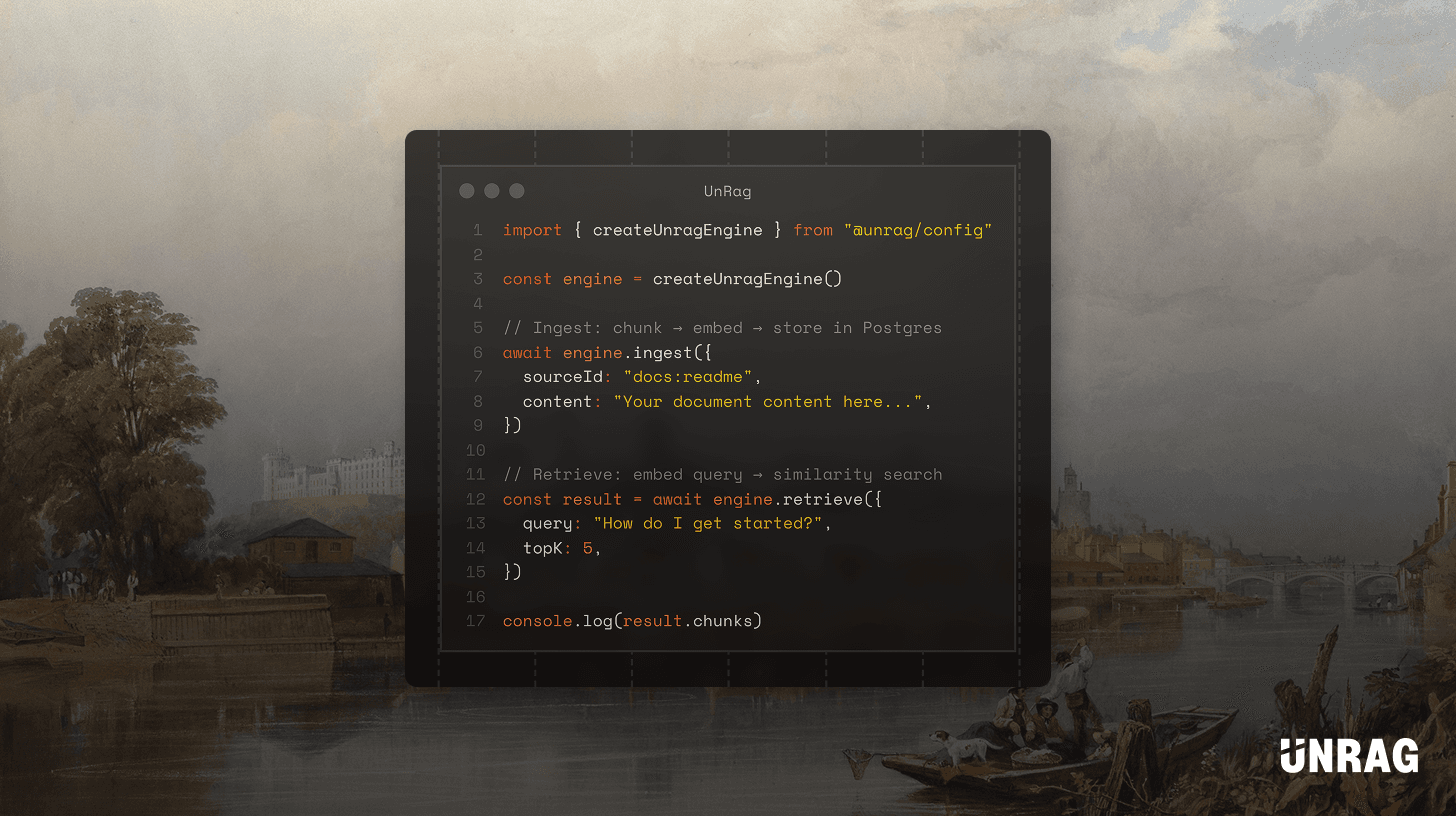
import { createUnragEngine } from "@unrag/config";
const engine = createUnragEngine();
// Ingest content: chunk it, embed each chunk, store in Postgres
await engine.ingest({
sourceId: "docs:intro",
content: "Hello from Unrag. This content will be chunked and embedded.",
});
// Retrieve relevant chunks for a query
const result = await engine.retrieve({ query: "hello", topK: 5 });
console.log(result.chunks);That's the core API. ingest() and retrieve() handle the fundamentals, plus optional rerank() for improving result precision and delete() for content management. Everything else (how you build prompts, how you integrate with chat, how you handle permissions) is up to you.
Unrag works with Postgres and pgvector because that's what most teams already have or can easily add. You manage your own migrations, you see the exact SQL being executed, and you can extend or modify the schema as your needs evolve.
