The RAG triangle: quality, latency, cost
The core tradeoff that drives most RAG architecture decisions.
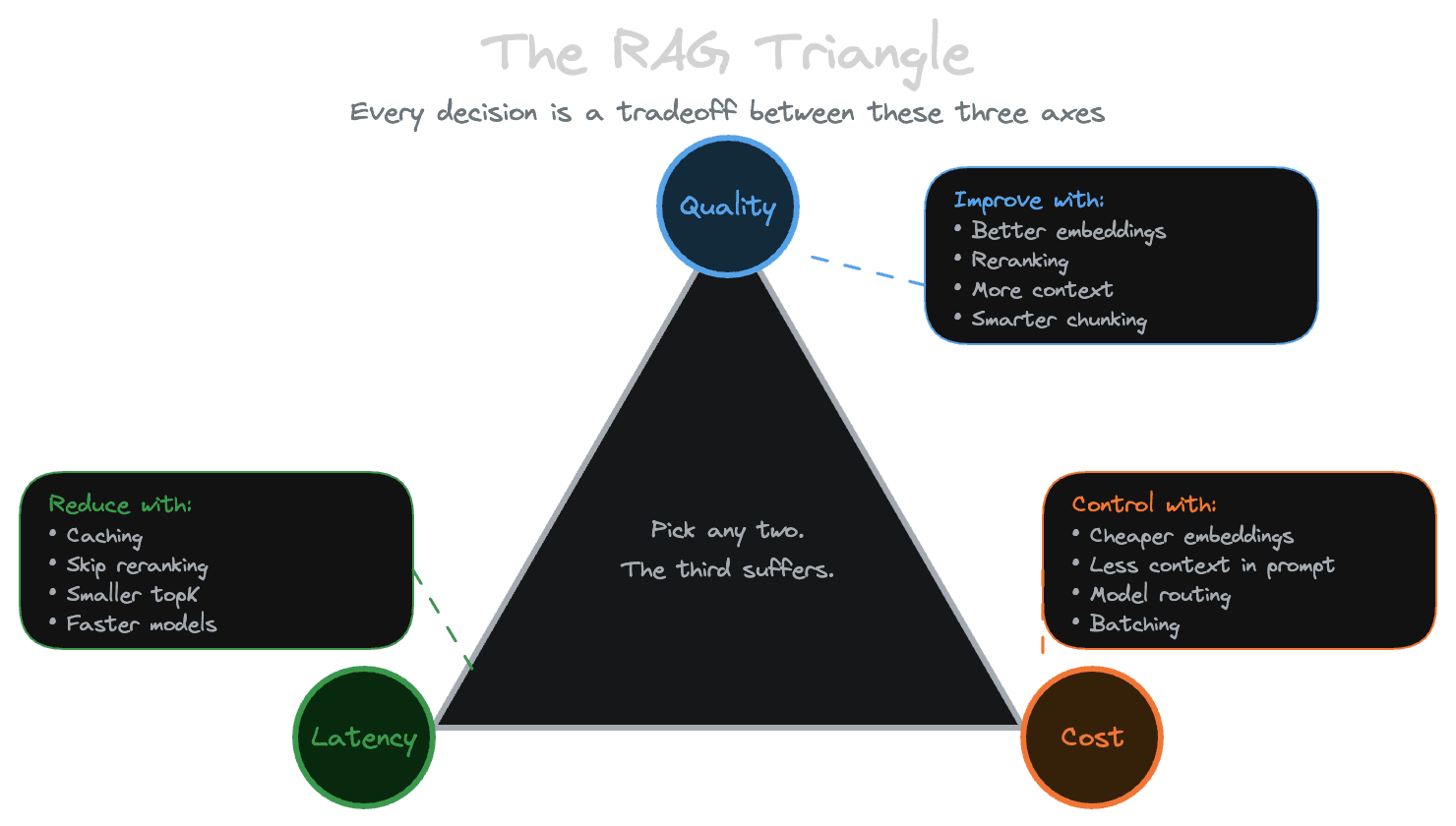
Every RAG system operates under three constraints that pull against each other: you want high-quality answers, you want them fast, and you want to keep costs reasonable. Improving one usually degrades another. Understanding this tradeoff—and knowing where the knobs are—helps you make intentional decisions rather than discovering constraints in production.
This chapter maps out the triangle and shows where you have control. Later modules go deep on specific techniques; here we establish the mental model.
The three axes
Quality is how well your system answers questions. This breaks down into several components: whether retrieval finds the right content (relevance), whether the model's answer matches the retrieved content (faithfulness), and whether the answer actually helps the user (usefulness). You can have high relevance but low faithfulness if the model ignores or misinterprets the context. You can have high faithfulness but low usefulness if the retrieved content wasn't what the user needed.
Latency is how long users wait for an answer. For chat interfaces, this means time-to-first-token (when typing starts appearing) and time-to-complete (when the full response is ready). For search interfaces, it's time to show results. Users have different tolerance depending on the context—they'll wait longer for a complex analysis than for a simple lookup—but latency always matters.
Cost is what you spend to run the system. This includes embedding costs (API calls to generate vectors), storage costs (indexes and databases), retrieval costs (compute for search), reranking costs (if you use a reranker), and generation costs (LLM API calls, which are usually the largest component). Costs scale with query volume and content size in ways that can surprise you.
The tradeoffs
These three axes aren't independent. Improving quality often increases latency and cost. Reducing latency often sacrifices quality. Cutting costs often degrades both.
Bigger chunks reduce the number of embeddings you generate (lower ingestion cost) but make retrieval less precise (lower quality). Smaller chunks improve precision but increase storage costs and can fragment information in ways that hurt usefulness.
More retrieval candidates improve recall—you're less likely to miss relevant content—but increase the latency of the retrieval step. They also increase reranking costs if you use a reranker, since the reranker has to score more candidates.
Reranking improves quality by making better relevance judgments than vector similarity alone, but adds 100-300ms of latency and costs money (API calls for hosted rerankers, compute for self-hosted ones).
Larger context windows let you include more retrieved content, which can improve answer quality, but increase generation costs (you pay per token) and can actually hurt quality if you include too much irrelevant content (the model gets confused or ignores parts of the context).
Better embedding models often improve retrieval quality but cost more per embedding. The difference between a cheap embedding model and a premium one might be 10x in cost for a modest improvement in relevance.
Better LLMs produce higher-quality responses but cost significantly more and often have higher latency. GPT-4 class models can cost 20-50x what GPT-3.5 class models cost for the same query.
Where the knobs are
You have control at every stage of the pipeline. Understanding which knobs affect which axes helps you tune the system.
Chunking affects quality (how well retrieval can find specific information) and ingestion cost (more chunks = more embeddings). Larger chunks are cheaper to ingest but less precise to retrieve. The sweet spot depends on your content and query patterns.
Embedding model choice affects quality (relevance of retrieval) and cost (per-embedding price). Some models also have different latency characteristics. You might use different models for different content types or query classes.
Index type and configuration affects retrieval latency and quality. Approximate nearest neighbor indexes (HNSW, IVF) are faster but can miss relevant results. Exact search is slower but complete. Index parameters control this tradeoff.
topK and thresholds affect quality and latency. Retrieving more candidates (higher topK) improves recall but slows down downstream steps. Thresholds that filter low-similarity results can improve precision but risk missing relevant content that doesn't score well.
Reranking affects quality, latency, and cost. Using a reranker improves relevance at the cost of added latency and expense. The number of candidates you rerank controls how much you spend.
Context packing affects quality and generation cost. Including more context gives the model more information but costs more tokens. Including less saves money but might miss relevant content.
Model selection affects quality, latency, and cost—often dramatically. Routing queries to different models based on complexity or confidence can optimize the tradeoff.
Making tradeoffs explicit
The worst outcome is discovering tradeoffs in production through user complaints or surprise bills. The better approach is to make tradeoffs explicit upfront.
Set budgets. Decide on acceptable latency (p95 under 2 seconds, for example), acceptable cost (less than $0.01 per query), and minimum quality bar (recall@10 above 0.8). Then design the system to meet those constraints.
Measure everything. You can't optimize what you don't measure. Log latency at each pipeline stage, track costs per query, and run regular evaluations to measure quality. Make these metrics visible.
Build fallbacks. When the system can't meet all three constraints simultaneously, have a defined degraded mode. Maybe you skip reranking under load to preserve latency. Maybe you use a cheaper model when costs exceed a threshold. Explicit fallbacks are better than implicit failures.
Evaluate tradeoffs before deploying changes. When you consider a change—different chunking, new embedding model, adding a reranker—evaluate its impact on all three axes. A change that improves quality but doubles cost might or might not be worth it, but you should know before you ship it.
The production mindset
In development, quality usually wins. You want the best possible answers, and you're running a few queries to test. In production, the tradeoffs become real. You're running thousands of queries, users are waiting, and the bill arrives monthly.
The modules ahead teach techniques for improving quality, reducing latency, and controlling costs. As you learn them, keep the triangle in mind. Every technique has a cost, and the art of production RAG is choosing the right tradeoffs for your specific situation.
Next module
With the orientation complete, you're ready to dive into the foundations. Module 1 covers the core primitives: embeddings, chunking, metadata, and indexing.