What is RAG?
Define RAG in operational terms and understand what problems it solves.
Retrieval-Augmented Generation is a pattern for making language models answer questions using your own data. Instead of relying solely on what the model learned during training, you search your content for relevant information, include it in the prompt, and ask the model to generate a response based on what you provided.
The pattern has three steps. First, you retrieve relevant information from your knowledge base—documentation, support tickets, product data, whatever you're working with. Second, you augment the model's input by adding that information to the prompt. Third, the model generates a response that's grounded in the context you supplied rather than invented from its training data.
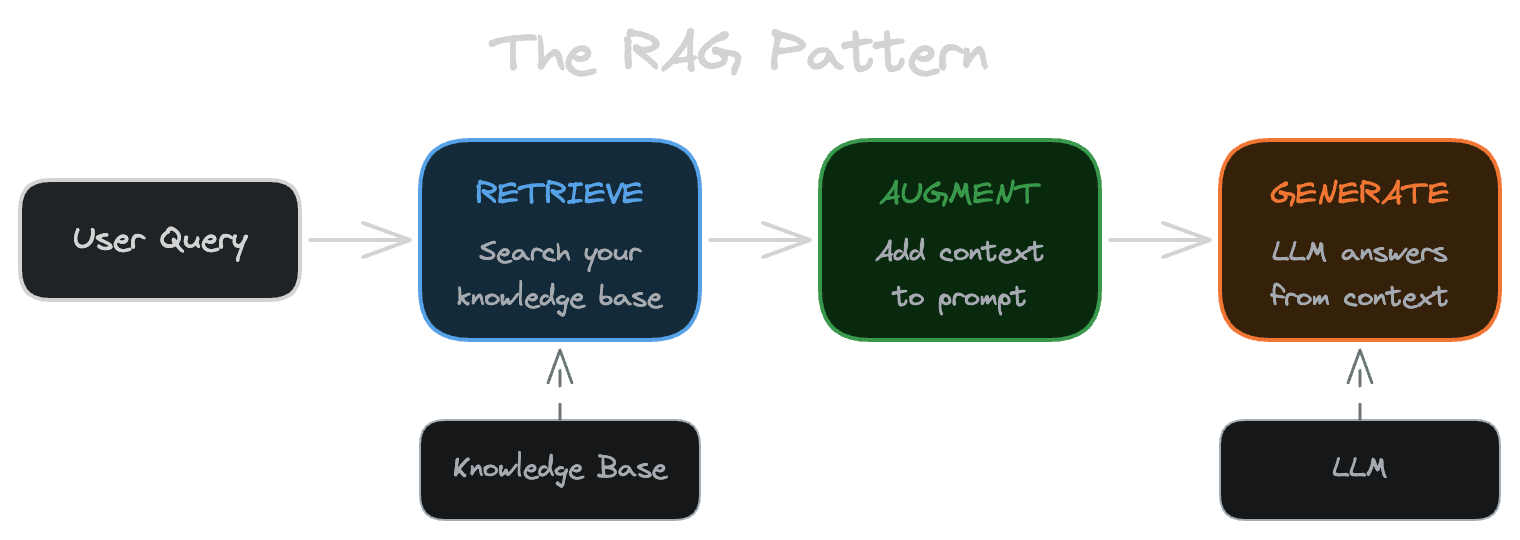
This sounds straightforward, and in a sense it is. The complexity comes from making it work reliably.
Why teams choose RAG
The most common alternative to RAG is fine-tuning: training a model on your specific data so it "knows" your information directly. Fine-tuning works for some use cases, but RAG has several advantages that make it the default choice for most production applications.
What RAG is not
RAG is often oversold as a solution to the "hallucination problem." It helps, but it doesn't eliminate the issue. A model can still hallucinate even with perfect context in front of it—it might misinterpret the information, combine facts incorrectly, or simply ignore what you provided. RAG gives the model evidence; it doesn't guarantee the model will use that evidence correctly.
RAG is also not a substitute for access control or data governance. The retrieval step surfaces information, but you need to ensure that information should be surfaced to that particular user. If your retrieval system returns sensitive documents to unauthorized users, the model will happily incorporate that information into its response.
Finally, RAG is distinct from tool use and agents, though they often appear together. RAG is about finding and using static information from your knowledge base. Tools let the model take actions or query live systems. Agents combine these capabilities with planning and multi-step reasoning. You can build RAG without agents, agents without RAG, or systems that use both. They're complementary patterns, not synonyms.
The failure modes you'll encounter
Understanding RAG's failure modes helps you build systems that handle them gracefully.
RAG systems have specific failure modes that require proactive mitigation. Being aware of these patterns helps you design systems that handle them gracefully.
Common failure patterns
-
Retrieval misses the right content. The user asks a question, the answer exists in your knowledge base, but your retrieval system doesn't find it. This is a false negative: the system fails silently by returning irrelevant results or nothing at all. The causes range from poor chunking (the relevant information is split across chunks in ways that don't match the query) to embedding model limitations (the query and document use different terminology for the same concept).
-
Retrieval returns plausible-but-wrong content. The user asks a question, your retrieval system returns documents that seem relevant but actually aren't, and the model generates a confident answer based on the wrong information. This is a false positive, and it's often worse than returning nothing because the user has no reason to doubt the response.
-
The model ignores the context. You retrieve the right documents, pack them into the prompt, and the model generates an answer that contradicts or ignores what you provided. This happens more often than you'd expect, especially with longer contexts or when the retrieved information conflicts with the model's training data.
-
The context attacks the model. If your knowledge base includes user-generated content or external data, that content might contain prompt injections—text designed to manipulate the model's behavior. The model treats retrieved content as trusted input, so malicious content in your knowledge base can hijack responses. See Security and prompt injection for mitigation strategies.
Each of these failure modes has mitigation strategies that we'll cover throughout the handbook. For now, the point is that RAG is not "retrieval + LLM = done." Building a system that works reliably requires understanding where things go wrong and designing around those failure modes.
Next
The next chapter maps out the components of a production RAG system, so you can see how these concepts translate into actual infrastructure.