Chunking foundations
Why chunking exists, what it optimizes for, and what a good chunk looks like.
Chunking is how you divide documents into the units that get embedded and retrieved. It seems like a formatting detail, but it's actually one of the most consequential decisions in a RAG system. The way you chunk determines what retrieval can find, how precise your results are, and how useful the retrieved content is as context for generation.
Why chunking matters
You might wonder why you can't just embed entire documents. There are two reasons.
Embedding quality degrades with length. Embedding models are trained on shorter texts, and their ability to capture meaning deteriorates as input length increases. A 500-word chunk produces a vector that represents its content reasonably well. A 10,000-word document produces a vector that's a fuzzy average of many topics, useful for broad similarity but not for finding specific information.
Retrieval needs granularity. When a user asks a question, you want to return the specific passage that answers it, not an entire document that mentions the topic somewhere. If your chunks are too large, you'll retrieve content that matches the query for the wrong reasons—the document is about the right general topic, but the relevant paragraph is buried in thousands of words of context.
Chunking creates units small enough to embed meaningfully and retrieve precisely, while large enough to contain useful information on their own.
The fundamental tradeoff
Smaller chunks give you more precise retrieval. Each chunk represents a narrower slice of content, so when it matches a query, it's more likely to be directly relevant. The downside is that small chunks lose context. A paragraph about configuring authentication makes less sense without the surrounding paragraphs about why you'd want to and what happens if you don't.
Larger chunks preserve more context but sacrifice precision. A large chunk is more likely to contain the answer to a query, but it's also more likely to contain a lot of irrelevant content along with it. When you pass that chunk to the LLM, the model has to sift through noise to find the signal.
Most applications land somewhere in the middle: chunks of 100-500 words, large enough to be useful on their own but small enough to retrieve specifically. The right size depends on your content, your queries, and how you use the retrieved chunks.
Overlap and why it helps
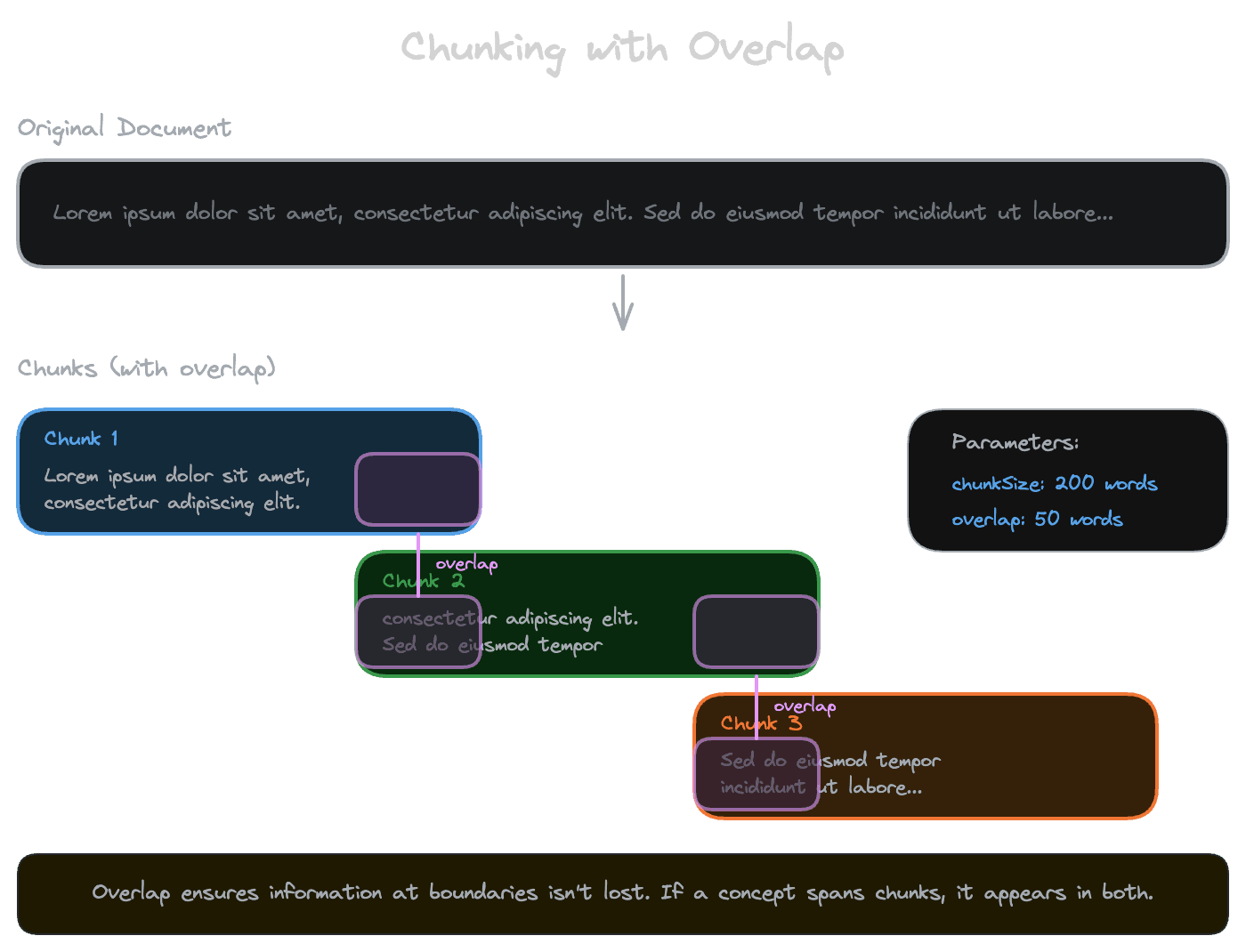
When you split a document into chunks, you often create overlap: each chunk shares some content with its neighbors. A 200-word chunk with 40 words of overlap means the last 40 words of chunk N are also the first 40 words of chunk N+1.
Overlap addresses the boundary problem. Without overlap, important information can fall at the split point, belonging to neither chunk in a way that makes it retrievable. The concept you're looking for might start at the end of one chunk and continue at the beginning of the next. Overlap ensures that content near boundaries appears in multiple chunks, increasing the chance that at least one of them captures the full idea.
The cost of overlap is redundancy. More chunks mean more embeddings to generate and store. Chunks that overlap substantially return nearly identical content in results. For most applications, 10-20% overlap is a reasonable starting point.
Content structure matters
The default approach to chunking—split by word count—ignores the structure of your content. Real documents have structure that chunking should respect.
Prose content (documentation, articles, help pages) is relatively forgiving. Paragraphs are natural semantic units, and splitting between paragraphs usually preserves meaning. Sentence-aware chunking that never splits mid-sentence improves on naive word-count chunking.
Code has structure that naive chunking destroys. A function split across two chunks won't be retrievable as a unit. Splitting inside a code block produces chunks that don't make sense on their own. Code-aware chunking respects function boundaries, keeps blocks intact, and might use different strategies for different languages.
Tables are especially problematic. Each row might be a meaningful unit, but the header row gives them context. Naive chunking that splits tables mid-row produces nonsense. Table-aware chunking might keep tables intact, split by row groups, or flatten tables into text.
Structured documents like legal contracts, academic papers, or API documentation have explicit sections. Section-aware chunking that splits at headings produces chunks with clear scope. The heading itself becomes metadata that helps with retrieval.
Mixed content (a document with prose, code examples, and tables) needs different handling for different parts. Sophisticated chunkers adapt their strategy based on content type.
The default chunker in any framework is usually naive about structure. If your content has meaningful structure, you'll get better results with a chunker that respects it.
With Unrag: Default chunking is configurable via unrag.config.ts. See chunking concepts for configuration options and custom chunker implementation.
What makes a good chunk
A good chunk has several properties:
It's self-contained enough to be useful. Someone reading just this chunk should understand what it's about. It shouldn't start mid-sentence or end mid-thought. It should include enough context to make sense without reading the surrounding chunks.
It represents a coherent topic. A chunk about one thing is easier to retrieve than a chunk about three things. When the chunk matches a query, it should match because it's about that query's topic, not because it incidentally mentions a keyword while being about something else.
It's the right size for your embedding model. Most embedding models have a token limit (8,192 tokens is common). Chunks that exceed this limit get truncated, losing information. Chunks that are much smaller than the limit might not provide enough context for a meaningful embedding.
It's the right size for your context window. If you're passing retrieved chunks to an LLM, you need to fit multiple chunks in the context. Smaller chunks let you include more of them. The right balance depends on how much context the model needs and how many tokens you can afford.
Evaluating chunking quality
How do you know if your chunking is working? The best signal comes from retrieval evaluation: given queries with known-relevant documents, does your system find them?
If you're seeing retrieval failures, chunking is often a factor. Look at the chunks that should have matched but didn't. Is the relevant content split across chunks in a way that dilutes it? Is the chunk so large that the relevant content is buried in noise? Is structure being destroyed in ways that hurt meaning?
You can also inspect chunks directly. Pick some documents and look at how they get chunked. Do the boundaries make sense? Would you be able to answer questions from each chunk, or does meaning depend on context that's not there?
Chunking is iterative. Your first approach probably won't be optimal. Build evaluation into your workflow so you can measure the impact of chunking changes.
Next
With embeddings and chunking covered, the next chapter addresses metadata: how you attach information to chunks that enables filtering, permissions, and richer retrieval strategies.