Grounding prompts and rules
Make the model use context, cite sources, and refuse when the evidence isn't there.
The whole point of RAG is to make the model answer from your content rather than its general training. But models don't automatically prioritize retrieved context over their parametric knowledge. Without explicit grounding instructions, they'll happily ignore your carefully curated context and answer from whatever they learned during training. Grounding prompts establish the rules: use the provided sources, cite them, and refuse to answer when the evidence isn't there.
The grounding system prompt
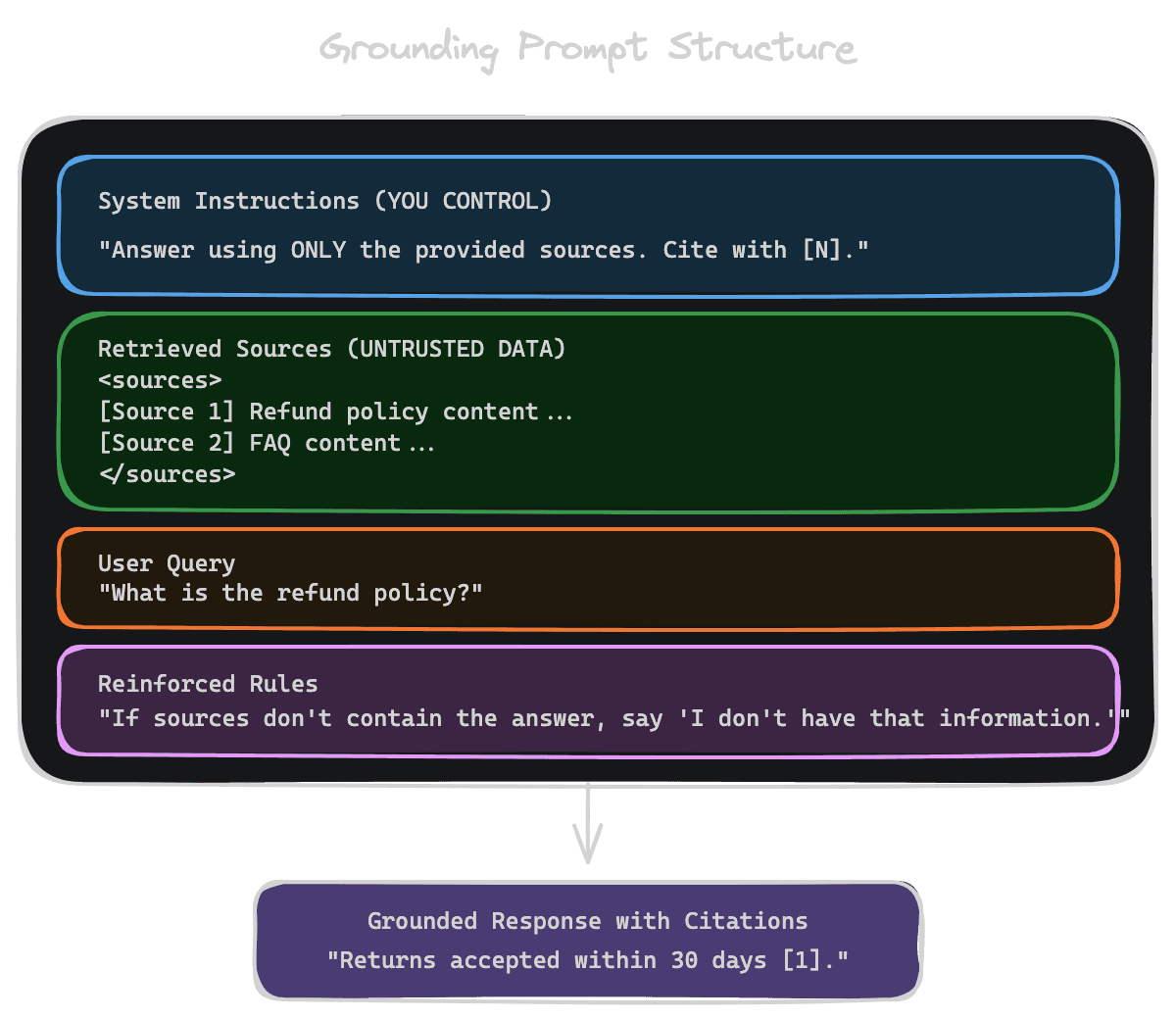
Your system prompt sets expectations for how the model should behave. For RAG, this means establishing several key principles:
Example grounding prompt:
You are a helpful assistant that answers questions using the provided sources.
Rules:
- Answer using ONLY information from the sources below
- Cite each claim with [Source N]
- If the sources don't answer the question, say "I don't have enough information to answer that"
- Don't make up information or use knowledge not in the sourcesWith Unrag: See Use with chat for complete prompt examples.
Rules that work versus rules that get ignored
Not all instructions are followed equally. Understanding what models respect helps you write effective prompts.
Specific, concrete rules work better than vague ones. "Cite using [1]" is clearer than "cite your sources." "Say 'I don't know'" is clearer than "acknowledge uncertainty."
Rules with clear structure are easier to follow. Numbered lists, explicit formats, and examples help the model understand exactly what you want.
Rules reinforced by format work better. If you ask for citations and provide sources with clear labels like "[Source 1]", the model can easily produce the expected output. If your sources are unlabeled walls of text, citation becomes harder.
Some rules conflict with the model's training. Models are trained to be helpful, which means they resist refusing to answer. Explicit refusal instructions need to be strong and repeated to overcome this bias.
Rules at the end of long prompts may be forgotten. Put critical instructions at the beginning and consider repeating key points.
Citation requirements and schema
Defining a clear citation schema makes citations reliable and parseable.
Decide on a format: [1], [Source 1], [[document-name]], or something else. Whatever you choose, be consistent and include it in your system prompt.
Show the model examples if the format is complex. If you want citations in a specific JSON structure, provide an example in your prompt.
Inline citations (after each claim) are more useful than end-of-response citations. They make verification easier and encourage the model to ground each statement.
Consider what you'll do with citations programmatically. If you need to parse them and link to sources, choose a format that's easy to regex or parse. [1] is trivial to extract; natural language references like "according to the refund policy document" are harder.
Validate citations in post-processing. Check that cited source numbers actually exist in the provided context. Flag or fix citations that reference non-existent sources.
Handling "no answer" cases
When the retrieved context doesn't contain the answer, the model should acknowledge this rather than hallucinate.
Define what "no answer" looks like. Provide the exact phrasing you want: "I couldn't find information about that in the provided sources" or "The sources don't cover this topic." Explicit phrasing prevents the model from inventing creative ways to avoid admitting ignorance.
Distinguish between "no relevant context" and "context exists but doesn't answer the specific question." The former might trigger a fallback search; the latter is a genuine knowledge gap in your content.
Consider offering alternatives. "I don't have information about X, but I found related information about Y" can be more helpful than a flat refusal, if you detect near-miss retrievals.
Clarifying questions
Sometimes the query is too ambiguous to answer well. The model can ask for clarification instead of guessing.
Enable clarifying questions in your prompt: "If the question is ambiguous or you need more information to provide a good answer, ask a clarifying question."
Set limits to prevent over-asking. You don't want every query to prompt "What specifically do you want to know?" Clarification should be reserved for genuinely ambiguous cases.
For some products, clarification isn't appropriate. A search interface might prefer "best guess" answers over a conversational back-and-forth. Match the interaction pattern to your product.
Testing grounding effectiveness
Evaluate whether your grounding prompts actually work.
Create test cases with queries that should be answerable from context, queries that aren't answerable (expecting refusal), and queries where the model might be tempted to use training data instead of context.
Measure citation accuracy: does the model cite sources? Are the citations correct? Does the cited source actually support the claim?
Measure refusal appropriateness: does the model refuse when it should? Does it refuse when it shouldn't?
Iterate on your prompts based on failure patterns. If the model consistently ignores a rule, make it more prominent, more specific, or differently phrased.
Next
With grounding established, the next chapter covers answer formats—how the structure of your response affects usefulness, trust, and evaluation.