Multi-turn chat and memory
Prevent retrieval degradation over time - summarize, rewrite queries, and scope memory intentionally.
Single-turn RAG is straightforward: user asks a question, you retrieve context, you generate an answer. Multi-turn chat introduces complexity. The user's third question might reference their first question. "What about returns?" only makes sense if you remember they were asking about Product X. But naively using the full conversation for retrieval causes problems—conversations drift, context windows fill up, and retrieval quality degrades.
The multi-turn challenge
In conversation turn five, the user asks "How long does that take?" The word "that" refers to something from earlier—maybe a refund process, maybe a shipping method. If you retrieve based only on "How long does that take?", you'll get garbage results. The query has no meaning without context.
But if you retrieve based on the entire conversation, you face different problems. Long conversations overflow context windows. Old topics contaminate retrieval for new topics. The embedding of a long conversation is a blurry average that matches nothing well.
Multi-turn RAG requires strategies for understanding what the user means now, while managing the history of what they've discussed before.
Query rewriting from conversation
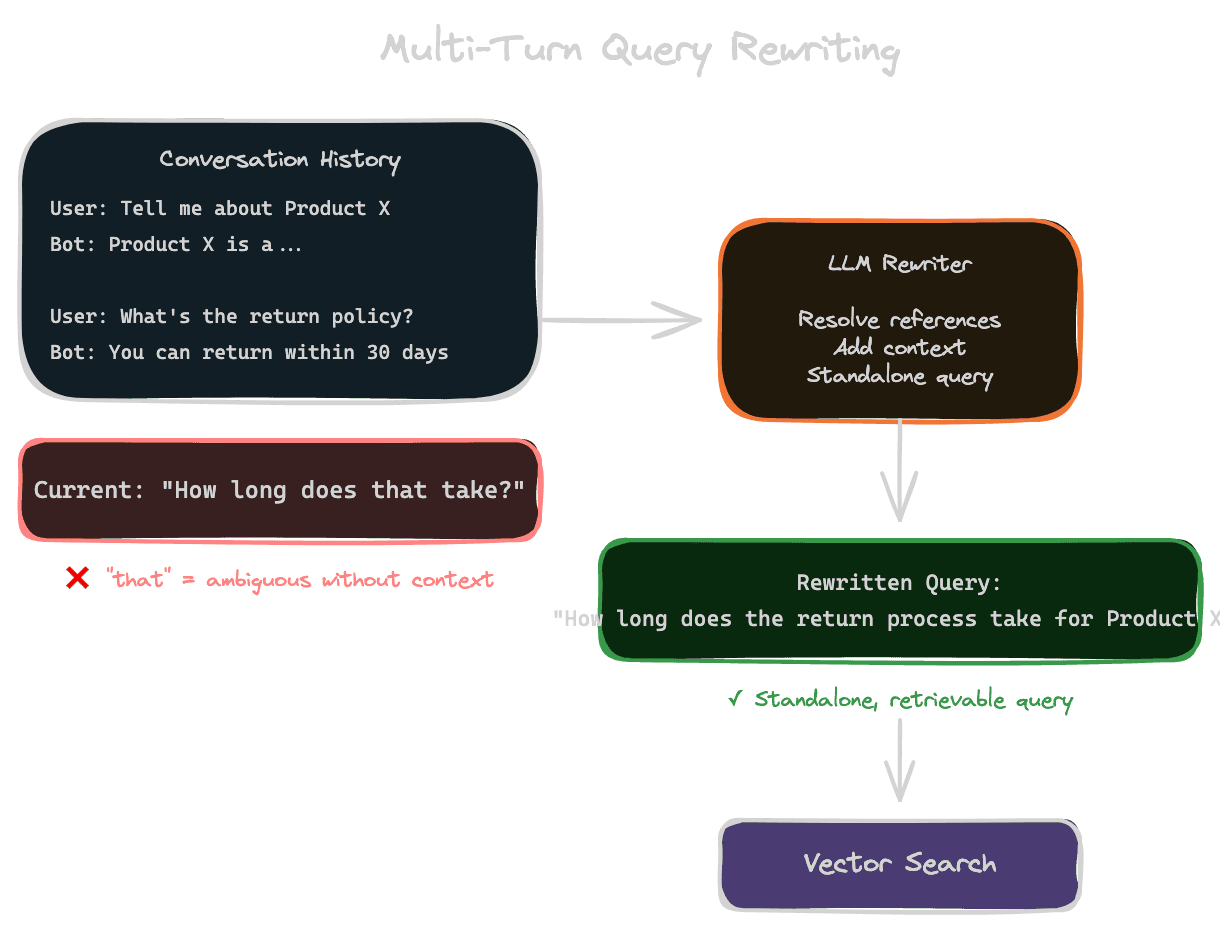
The most common approach is query rewriting: before retrieval, use the conversation history to rewrite the current query into a standalone form that captures the full intent.
"How long does that take?" becomes "How long does the refund process take for Product X?" once you incorporate the context that the user was asking about refunds for Product X.
This rewriting happens before retrieval. You use an LLM to transform the ambiguous query into a clear one, then retrieve using the rewritten query, then generate the answer.
The rewrite prompt might look like: "Given the conversation history and the user's latest message, rewrite the message as a standalone query that captures the full intent. Include relevant context from the conversation."
Rewriting adds latency (one LLM call before retrieval) but dramatically improves retrieval quality for conversational queries.
What to retrieve on
There are several options for what query to use for retrieval in multi-turn scenarios.
Using only the last message is fast but fails for references like "that" or "it" that need context.
Using the rewritten query (as described above) handles references well and is the most common production approach.
Using the full conversation as the retrieval query can work for short conversations but degrades as conversations grow. The embedding becomes diffuse and matches poorly.
Using a conversation summary provides middle ground: compress the conversation to key topics and use that as context for the query. This handles longer conversations but adds complexity.
The right choice depends on your typical conversation length and how much reference resolution you need.
Avoiding topic drift
Conversations naturally drift between topics. A user might start asking about refunds, then switch to asking about shipping, then come back to refunds. If your retrieval treats the whole conversation as one topic, you'll retrieve context that mixes all topics poorly.
Topic detection can help. Identify when the user has switched topics and scope retrieval appropriately. If the user is asking about shipping now, don't let refund context from earlier contaminate retrieval.
Explicit scoping lets users signal what they're asking about. "About shipping—how long does it take?" is easier to handle than "How long does that take?"
Reset points in the conversation can clear accumulated context. Some products let users start a "new topic" explicitly, which clears retrieval context while preserving some conversational memory.
Conversation summarization
For long conversations, you can't keep everything in context. Summarization compresses earlier turns into a shorter representation.
Rolling summaries update after each turn: the summary plus recent turns fit in your context budget. When turns age out, they become part of the summary.
Topic-based summaries organize by subject: "User discussed refunds for Product X (outcome: explained 30-day policy). User then asked about shipping (outcome: pending)." This preserves key information while compressing.
Selective retention keeps important turns verbatim while summarizing routine ones. The turn where the user specified Product X might be worth keeping; the turn where you said "You're welcome" isn't.
Compounding errors
Errors in multi-turn RAG compound across turns. If turn 2's query rewrite misunderstands the context, turn 3 builds on that misunderstanding. By turn 5, the conversation may have drifted far from user intent.
Monitor for drift. If the user suddenly re-states something from earlier, they may be correcting a misunderstanding. Treat explicit corrections as signals to reset context.
Confirm understanding periodically. For complex conversations, the system can occasionally verify: "Just to confirm, you're asking about refunds for your order from last week?" This catches drift early.
Make it easy to restart. Users should be able to say "Let's start over" or "I want to ask about something else" to clear accumulated context.
Memory beyond conversation
Some products maintain memory across sessions: remembering user preferences, previous purchases, or past questions.
Long-term memory enables personalization but adds complexity. What should be remembered? How long? How does it affect retrieval?
Retrieve from memory as context. If the user has stated preferences ("I'm a vegetarian"), retrieve that when it's relevant. This feels magical when it works.
But be careful with privacy. Remembering too much feels creepy. Give users control over what's remembered and the ability to forget.
Separate memory retrieval from document retrieval. User facts and document facts are different kinds of context. Manage them separately.
Next
Multi-turn chat extends RAG to conversations. The next chapter covers tools and agents—how retrieval composes with other capabilities like API calls and code execution.