What to measure
Separate retrieval quality from answer quality, and choose metrics that reflect product risk.
RAG evaluation is tricky because the pipeline has multiple stages, and a failure at any stage can produce a bad result. If you only measure the final answer, you can't tell whether problems come from retrieval, reranking, or generation. If you only measure retrieval, you might miss that your generation is distorting perfectly good context. Effective evaluation measures at multiple points, using metrics appropriate to each stage.
The evaluation layers
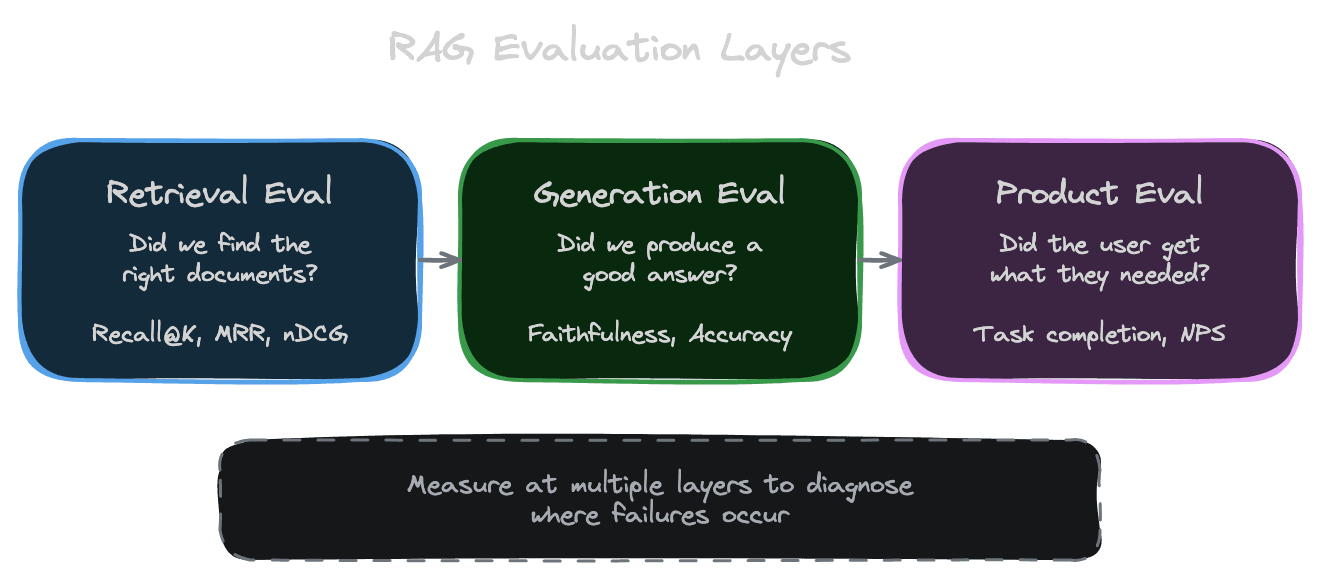
Think of RAG evaluation as measuring at three layers.
Retrieval evaluation asks: did we find the right documents? This is independent of what the LLM does with them. Even with a perfect LLM, bad retrieval produces bad answers because the right information isn't in context.
Generation evaluation asks: did the LLM produce a good answer from the context? This measures the quality of the response given what was retrieved. Even with perfect retrieval, a confused or hallucinating LLM produces bad answers.
End-to-end evaluation asks: did the user get what they needed? This is the ultimate measure but is harder to attribute—if the answer is wrong, was it retrieval or generation?
Measuring at multiple layers lets you diagnose where failures occur and focus improvement efforts appropriately.
Retrieval metrics
Standard information retrieval metrics apply to the retrieval stage.
These metrics require ground truth: for each test query, you need to know which documents are relevant. Creating this ground truth is covered in the next chapter.
With Unrag: Use the built-in eval framework to measure these metrics systematically.
What retrieval metrics miss
Retrieval metrics assume you know which documents are relevant, but this isn't always clear.
Relevance is often continuous, not binary. A document might be somewhat helpful, very helpful, or tangentially useful. Binary recall/precision doesn't capture this nuance. nDCG handles graded relevance but requires graded labels.
Multiple documents might answer a query equally well. Retrieving document B instead of document A isn't a failure if both contain the answer. But if your ground truth only marks A as relevant, you'll penalize retrieving B.
Retrieval metrics don't measure answer quality. A document might be relevant in the IR sense (it's about the topic) but not actually answer the specific question. Retrieval can succeed while the answer still fails.
Use retrieval metrics as diagnostics, not as the sole quality measure.
Answer metrics
Evaluating generated answers is harder than evaluating retrieval because there's more subjectivity.
Faithfulness (or groundedness) measures whether the answer is supported by the retrieved context. An unfaithful answer makes claims not found in the sources, which is hallucination. Measuring faithfulness requires checking each claim against the provided context.
Citation accuracy measures whether citations are correct. Does the cited source actually support the claim? Are all claims cited? Citation accuracy is a concrete proxy for groundedness that's relatively easy to automate.
Correctness measures whether the answer is factually right. This requires knowing the true answer, which may not always be available. For factual questions, correctness can be measured against a gold-standard answer.
Completeness measures whether the answer covers all aspects of the question. A partial answer might be correct but incomplete. This matters more for complex questions with multiple parts.
Usefulness or helpfulness measures whether the answer actually helps the user. An answer can be correct but not useful (too verbose, wrong level of detail, doesn't address the real need). This is subjective and typically requires human judgment or a well-designed LLM-as-judge rubric.
Product metrics
Beyond technical quality, you should measure impact on user outcomes.
Task completion measures whether users accomplish their goals. For a support chatbot, this might be whether the user's issue was resolved without escalation. For a research tool, this might be whether users found what they were looking for.
Deflection rate (for support applications) measures what fraction of queries are fully handled by the RAG system versus requiring human intervention. Higher deflection means more value from automation.
Time to resolution measures how long users take to get answers. A good RAG system should reduce time compared to manual search.
User satisfaction can be measured through ratings, surveys, or net promoter score. Direct user feedback is valuable but can be noisy and biased toward users who bother to respond.
Trust and adoption over time show whether users continue using the system. High abandonment suggests quality problems even if individual queries seem to work.
Choosing what to prioritize
You can't optimize everything. Choose metrics based on your product's risk profile.
For high-stakes applications (medical, legal, financial), prioritize faithfulness and correctness. Wrong answers are costly. You'd rather refuse to answer than hallucinate.
For efficiency applications (deflecting support tickets), prioritize task completion and deflection. Some noise is acceptable if overall throughput improves.
For research applications, prioritize recall and completeness. Missing relevant information is worse than including some noise. Users will filter results themselves.
Define success criteria before you build. If you don't know what good looks like, you can't evaluate effectively.
Next
With metrics defined, the next chapter covers building evaluation datasets—the queries and ground truth you need to actually measure these metrics.