Online evaluation and feedback loops
A/B tests, human review, and feedback capture that improves the system over time.
Offline evaluation measures quality against a fixed dataset. Online evaluation measures quality in production against real users and real queries. Both are necessary: offline eval catches problems before ship, online eval catches problems that only appear in the wild. Online evaluation also creates feedback loops—learning from production to improve future versions.
Why online evaluation matters
Real usage differs from test datasets. Users ask questions you didn't anticipate. They phrase things in unexpected ways. They have context from previous interactions or external knowledge. Distribution shift means your offline eval may not predict production quality perfectly.
Online evaluation captures this reality. You measure quality on the actual distribution of queries your system faces, not a curated sample.
Online evaluation also enables experimentation. You can test changes on a subset of traffic and measure real impact before full rollout.
A/B testing for RAG
A/B testing compares two variants by randomly assigning users to each and measuring outcomes.
For RAG, you might A/B test a new embedding model, reranking strategy, or prompt. Half of users get variant A (control), half get variant B (treatment). You measure quality metrics on each group and compare.
Randomization must be at the right level. For session-coherent experiences, randomize by user or session, not by query. You don't want a user's conversation to switch between variants mid-stream.
Sample size matters. You need enough traffic in each variant to detect meaningful differences. If a 5% quality improvement is meaningful, calculate the sample size needed to detect it with statistical significance.
Some things are dangerous to A/B test. Changes that might produce harmful outputs shouldn't be tested on real users without safeguards. Use offline eval first to verify safety.
What you can safely randomize
Not all changes are good A/B test candidates.
Safe to test: prompt variations, reranking models, retrieval parameters (topK, thresholds), answer formatting, UI changes. These affect quality or experience but don't introduce new risk categories.
Risky to test without safeguards: new content sources, major model changes, changes that might affect accuracy on sensitive topics. Use staged rollouts with monitoring instead of pure A/B tests.
Never A/B test: security-sensitive changes, access control logic, anything where a bug in one variant could cause harm. These need thorough offline validation, not live experimentation.
Feedback UX
Users can provide explicit feedback that tells you about quality. Design your UI to capture this feedback without being intrusive.
Thumbs up/down is the simplest signal. It's low-friction (one click) but low-information (you don't know why). Still, thumbs-down on specific responses is valuable for identifying problems.
Specific feedback options provide more information: "Wrong answer," "Outdated information," "Missing source," "Too verbose," "Not relevant." These take more effort from users but tell you what went wrong.
Free-text feedback lets users explain in their own words. This is rich but unstructured and hard to analyze at scale. Use it for qualitative insights, not metrics.
Corrections are the most valuable feedback: "The answer said X, but it should be Y." This gives you ground truth for future evaluation. Make it easy for users to correct wrong answers.
Implicit feedback comes from behavior: Did the user click a source? Did they ask a follow-up question rephrasing the same thing (suggesting the first answer didn't help)? Did they abandon the conversation? Behavioral signals don't require explicit action.
Closing the feedback loop
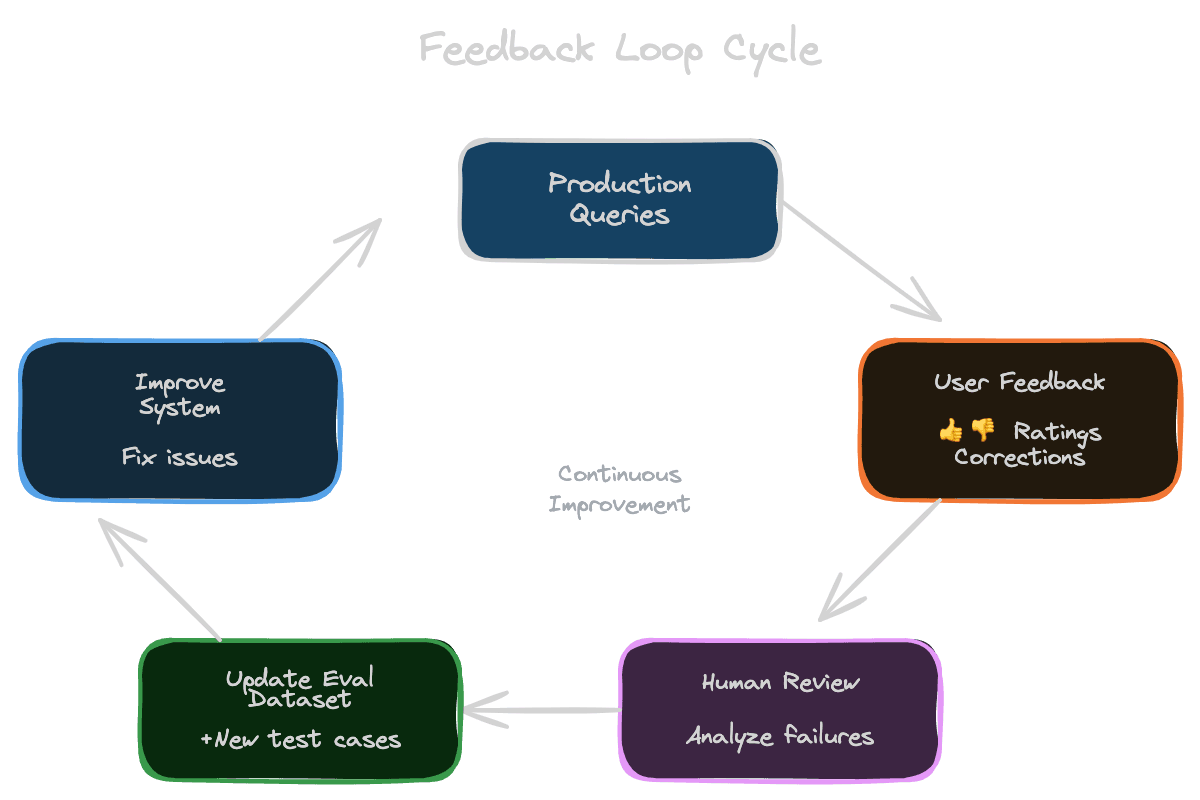
Feedback is only valuable if you use it. Build processes to turn feedback into improvements.
Route feedback to review. Negative feedback should trigger human review. Understand what went wrong—was it retrieval, generation, or something else?
Create new eval examples. Every feedback instance is a potential eval case. If a user reported a wrong answer, that query plus the correct answer becomes a test case.
Track feedback trends. If feedback on a particular topic or query type is consistently negative, there's a systematic problem to investigate.
Close the loop with users. If users report problems and you fix them, let users know (if appropriate). This encourages continued feedback.
Measure feedback volume as a metric. If negative feedback increases after a change, even if your offline metrics look fine, something might be wrong.
Human review programs
For high-stakes applications, establish regular human review of production outputs.
Sample and review a random set of queries periodically. Have reviewers score answers on your quality dimensions (correctness, faithfulness, usefulness). This provides ground-truth quality measurement that doesn't depend on user feedback.
Review negative feedback cases in depth. When users report problems, understand root causes. Is it a systematic issue or a one-off edge case?
Compare human judgments to automated metrics. If humans say quality is bad but your metrics say it's good, your metrics are wrong. Use human review to calibrate your automated evaluation.
Production monitoring
Beyond explicit evaluation, monitor production for quality signals.
Error rates: Are requests failing? Are there parsing errors or format problems?
Latency: Is the system responding quickly enough? Latency spikes might indicate retrieval problems.
Retrieval hit rates: Are queries finding relevant content? High rates of low-scoring retrieval might indicate content gaps or query-content mismatch.
Refusal rates: How often does the system say "I don't know"? Too high might indicate retrieval problems; too low might indicate over-confidence.
Citation rates: Are answers citing sources? Declining citation rates might indicate generation drift.
Set up alerts for anomalies. If any metric suddenly changes, investigate.
Next
Human review is valuable but expensive. The next chapter covers LLM-as-judge—using language models to automate quality assessment at scale.