Hybrid retrieval (BM25 + vectors)
When lexical matching is required, how to combine it with semantic retrieval, and how to evaluate the blend.
Vector search finds content by meaning, which is powerful but not perfect. When a user searches for error code "ERR_AUTH_403" or product SKU "WH-1000XM5", semantic similarity isn't what they need—they need exact matching. Hybrid retrieval combines the semantic power of vectors with the precision of keyword search, covering cases that either approach alone would miss.
Where vectors fail
Vector embeddings capture meaning, but meaning isn't always what matters. Several common query types are poorly served by semantic search alone.
Identifiers and codes have no semantic content to embed. "ERR_AUTH_403" means "permission denied" to someone who knows your system, but the embedding model doesn't know that. It sees a string of characters that looks vaguely technical. A document explaining this error code might not be retrieved because the semantic similarity between the query and the document depends on how much surrounding context was embedded.
Proper nouns and specific terminology can suffer from vocabulary gaps. If your embedding model wasn't trained on your product names or industry-specific terms, it might not place them near semantically appropriate content.
Exact-match expectations exist for some queries. When a user searches for a specific phrase they remember reading, they expect the document containing that phrase to rank highly. Vector search might return documents about the same topic that happen not to contain that phrase.
Rare terms that appear infrequently in the training data produce weaker embeddings. The model doesn't have enough examples to learn robust representations, so similarity judgments are unreliable.
These aren't failures of your embedding model specifically—they're limitations of the semantic similarity approach in general.
BM25 and keyword search basics
BM25 (Best Matching 25) is the standard algorithm for keyword-based retrieval. It's what traditional search engines like Elasticsearch use under the hood.
BM25 scores documents based on term overlap: how many of the query terms appear in the document, weighted by how rare those terms are in the overall corpus. A document containing a rare term from the query scores higher than one containing only common terms. The algorithm also accounts for document length, so long documents don't have an unfair advantage just because they contain more words.
Keyword search finds documents that contain the query terms, which is exactly what you want for identifiers, codes, and exact phrases. It fails when the right document uses different words than the query—the vocabulary mismatch problem that semantic search solves.
By combining both approaches, you get semantic understanding for conceptual queries and term matching for specific lookups.
Fusion strategies
There are several ways to combine vector and keyword results into a single ranked list.
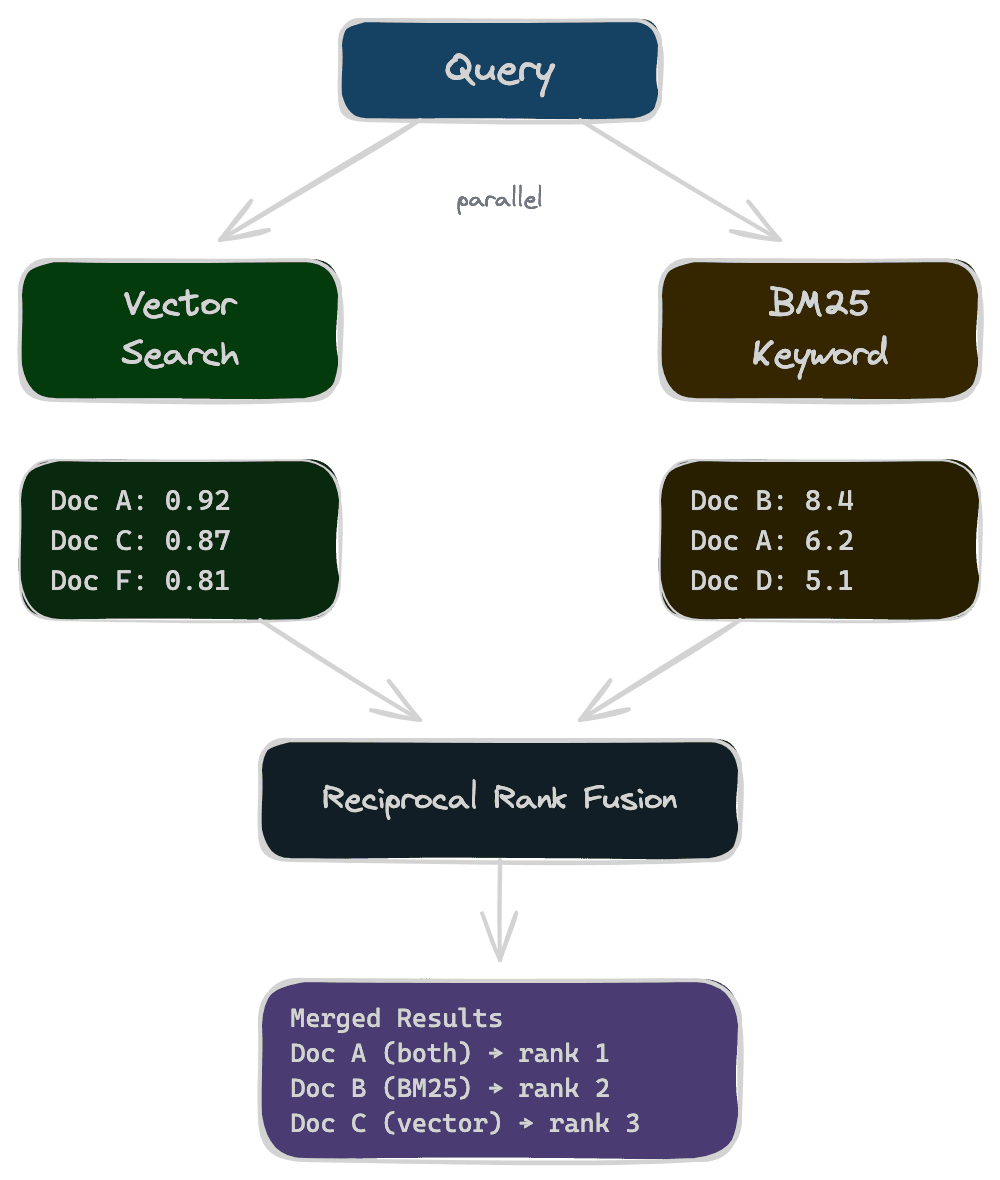
Reciprocal Rank Fusion (RRF) combines rankings rather than scores. Each result gets a score based on its rank in each system: if a document is rank 3 in vector search and rank 7 in BM25, its RRF score combines those ranks (typically as 1/(k+rank) where k is a constant like 60). Documents appearing in both lists get boosted; documents appearing in only one still contribute. RRF is robust because it doesn't require normalizing scores between systems.
Linear combination adds weighted scores: final_score = α * vector_score + (1-α) * bm25_score. This requires normalizing both scores to comparable ranges (both 0-1, for example). The weight α controls the balance—0.7 favors vectors, 0.3 favors keywords. Finding the right α requires experimentation on your specific queries and content.
Cascade retrieval runs one system first, then uses the other to rerank or filter. You might retrieve top-100 from vectors, then score those with BM25 and rerank. Or retrieve from both systems and take the union. Cascades let you tune each stage independently.
Conditional routing chooses one system based on query characteristics. If the query contains what looks like an identifier (specific character patterns), route to keyword search. Otherwise, use vectors. This adds complexity but can improve quality when query types are clearly distinguishable.
No fusion strategy is universally best. RRF is a good default because it's simple and robust. Tune from there based on evaluation results.
Implementing hybrid search
Most vector databases support hybrid search natively or through extensions. Postgres with pgvector can combine with full-text search using tsvector. Elasticsearch has dense_vector fields alongside traditional text fields. Purpose-built vector databases like Pinecone, Weaviate, and Qdrant have hybrid search features.
The implementation pattern is typically: run both searches in parallel, combine results using your chosen fusion strategy, and return the merged ranked list. Running in parallel avoids adding latency—you pay the time of the slower search, not both added together.
If your stack doesn't support native hybrid search, you can implement it at the application level: retrieve from both systems, merge results in code, and apply fusion. This adds some complexity but gives you full control over the fusion logic.
Evaluating hybrid performance
Hybrid search adds a dimension to evaluate: you need to measure how the blend performs compared to each system alone.
Create evaluation queries that cover both semantic and keyword-oriented cases. Include queries where you expect vectors to excel (conceptual questions, paraphrases) and queries where you expect keywords to excel (identifiers, exact phrases, rare terms).
Measure recall and precision for vectors alone, BM25 alone, and the hybrid blend. If the blend outperforms both individual systems across query types, your fusion is working. If it underperforms one system on certain queries, your fusion weights might need adjustment, or you might benefit from conditional routing.
Watch for cases where the blend is worse than the better individual system. This happens when noise from the weaker system pulls down overall quality. Adjusting fusion weights or using thresholds to exclude low-scoring results can help.
When to skip hybrid
Hybrid search adds complexity. It's worth the cost when keyword matching genuinely improves quality for a meaningful portion of your queries.
If your queries are almost entirely conceptual (questions about how things work, requests for explanations), and your content doesn't include identifiers or exact-match scenarios, pure vector search might be sufficient. Run an evaluation before adding hybrid complexity.
If you're already achieving high recall with vectors and your failure cases aren't keyword-related, hybrid won't help. Analyze what's actually failing before assuming the solution.
Next
With retrieval handling both semantic and keyword matches, the next chapter covers query transformation: rewriting and decomposing queries to improve recall on complex or ambiguous questions.