Retrieval debugging playbook
A repeatable method to diagnose false positives/negatives and improve retrieval without guesswork.
Retrieval failures can be mysterious. A user asks a reasonable question, the answer exists in your knowledge base, and the system returns wrong or empty results. Without a systematic approach, debugging becomes trial and error. This chapter provides a repeatable method for diagnosing and fixing retrieval problems.
The failure taxonomy
Not all retrieval failures are the same. Before investigating, classify what type of failure you're dealing with.
False negatives occur when relevant content exists but isn't retrieved. The user asks about topic X, you have content about X, but retrieval returns content about Y or nothing at all. The answer is in your index; retrieval failed to find it.
False positives occur when irrelevant content is retrieved and used. The user asks about topic X, retrieval returns content about Y (which mentions X tangentially), and the LLM generates an answer about Y. Retrieval found something, but it was wrong.
Permission failures occur when the right content exists but the user can't access it. This might look like a false negative to the user, but the cause is access control, not retrieval quality.
Freshness failures occur when outdated content is retrieved instead of current information. The content was correct at some point; it's wrong now because it's stale.
Coverage gaps are when the content simply doesn't exist. The user asks something your knowledge base doesn't cover. This isn't a retrieval failure; it's a content gap. The correct response is "I don't have information about that," not a retrieval fix.
Correctly classifying the failure type points you toward the right investigation path.
The diagnostic trace
For any specific failure, capture a diagnostic trace: what happened at each stage of the pipeline.
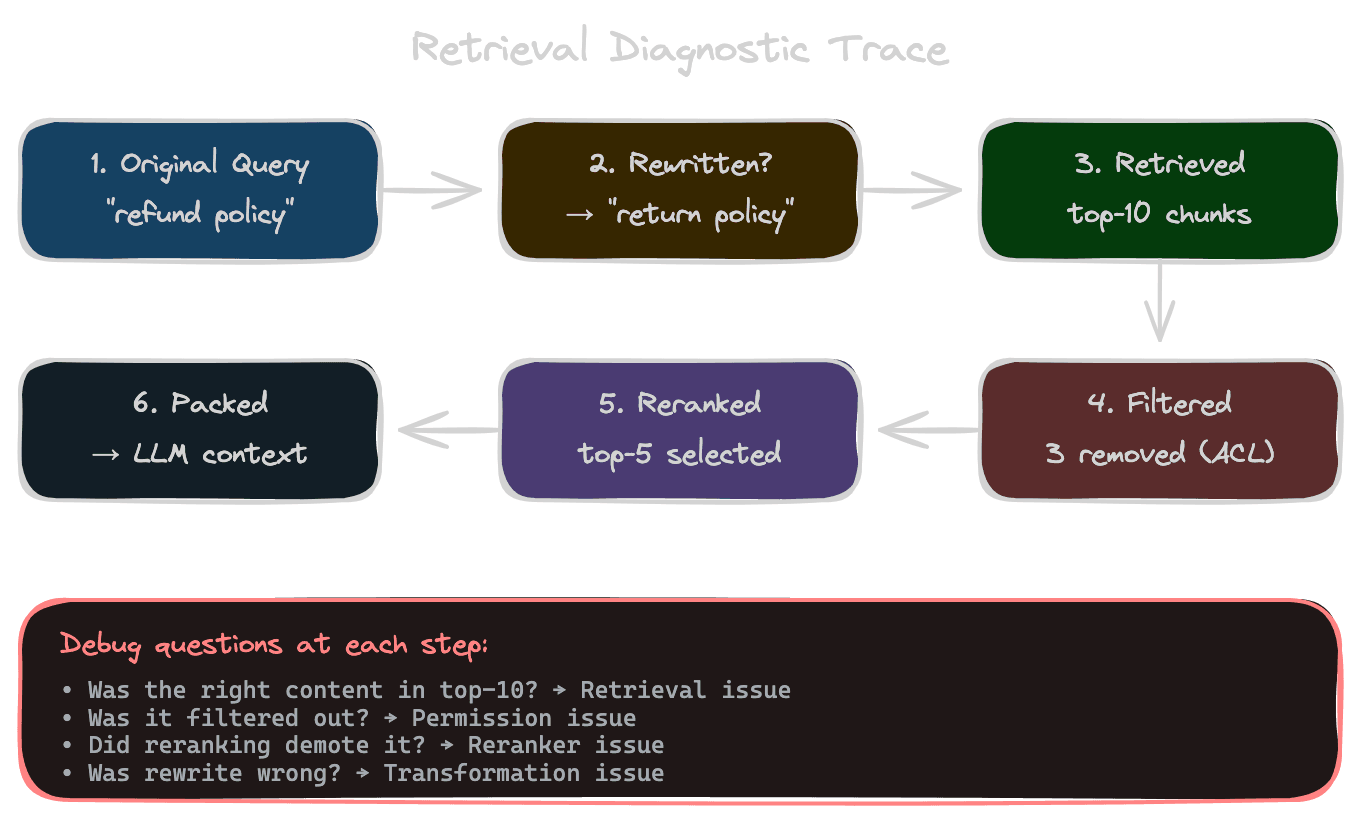
Start with the query: what exactly did the user ask? Was it rewritten? If so, what was the rewritten form? Query transformation issues can cause failures that look like retrieval problems.
What was retrieved? List the top-10 chunks by score, with their source documents and similarity scores. Did the right content appear at all? If so, at what rank? If not, what appeared instead?
Were filters applied? What permissions did the user have? Did filtering exclude content that would have been relevant?
If reranking was used, how did reranking change the order? Did it promote or demote the right content?
What was passed to the LLM? After all processing, what chunks made it into context?
This trace tells you where the pipeline broke. If the right content was in top-10 but not top-5 after reranking, you have a reranking issue. If the right content wasn't in top-50 at all, you have a retrieval issue. If it was filtered out, you have a permissions issue.
Diagnosing false negatives
The relevant content exists but wasn't retrieved. Investigate why.
Check the query-chunk similarity directly. Embed the query, embed the chunk that should have matched, and compute similarity. If similarity is low, you've identified the problem: the embedding space doesn't place them close together. Causes include vocabulary mismatch (query uses different words than the chunk), chunking issues (the relevant information is fragmented across chunks), or embedding model limitations (the model doesn't understand your domain).
Check if the chunk is indexed. A trivial failure mode: the content you think is in the index isn't actually there. Query your database directly to confirm the chunk exists.
Check filter interactions. Was the chunk excluded by a filter? Metadata or permission filters might be too restrictive.
Check query transformation. If queries are rewritten, was this query rewritten in a way that moved it away from the relevant content?
Once you identify the cause, the fix depends on the root issue: adjust chunking, add synonyms or query expansion, fine-tune embeddings for your domain, or correct filtering logic.
Diagnosing false positives
Irrelevant content was retrieved and used. Investigate why it ranked highly.
Check what made the irrelevant chunk score well. Look at the chunk text. Does it contain query keywords without being about the query topic? Is it from a generic document (like a table of contents) that mentions many topics?
Check for threshold issues. Was the irrelevant content above your similarity threshold? If your threshold is too low, noise sneaks through.
Check chunk quality. Is the chunk poorly constructed—too large, containing multiple topics, or including boilerplate? Bad chunks cause false positives.
Check for duplication or popularity bias. If the same content appears in multiple chunks (duplication) or a generic page ranks highly for many queries, you have systematic false positives from content issues.
Fixes include adjusting thresholds, improving chunking, cleaning boilerplate from content, or implementing deduplication.
Creating reproducible test cases
For each failure you diagnose, create a reproducible test case: the query, the expected relevant chunk(s), and the assertion that those chunks should appear in retrieval results.
These test cases become your evaluation set. Before changing retrieval configuration, run your test cases. After changes, run them again. Did the failures you fixed stay fixed? Did you introduce regressions?
Over time, you build a collection of test cases representing known failure modes. This set is invaluable for validating changes and catching regressions.
Systematic improvement workflow
When you identify a pattern of failures (not just one query, but a category of queries failing similarly), address it systematically.
First, quantify the problem. How many queries in your evaluation set exhibit this failure pattern? This is your baseline.
Second, hypothesize a fix. Based on your diagnosis, what change should address the failures? Better chunking, query expansion, threshold adjustment, filtering changes?
Third, implement and measure. Apply the fix and run evaluation. Did the failure rate for this pattern decrease? Did you introduce regressions in other patterns?
Fourth, validate in production. Deploy and monitor. Do real user queries show improvement? Watch for unexpected consequences.
Document what you learned. The pattern, the root cause, the fix, and the results. This documentation helps you recognize similar issues in the future and builds institutional knowledge.
Common root causes summary
As you debug, you'll find that most failures trace back to a short list of causes.
Query-document vocabulary mismatch: users phrase things differently than content is written. Solutions include query expansion, hybrid search, and multi-representation indexing.
Chunking that fragments relevant information: the answer is split across chunks, so no single chunk scores highly. Solutions include adjusting chunk size, improving boundaries, and parent-child retrieval.
Thresholds that are miscalibrated: too high and you get false negatives; too low and you get false positives. Solution is empirical calibration with representative queries.
Missing or stale content: the answer doesn't exist or is outdated. Solution is content coverage and freshness processes, not retrieval tuning.
Filter misconfiguration: permissions exclude content that should be visible, or include content that shouldn't be. Solution is ACL auditing and testing.
Knowing these common causes helps you form hypotheses faster when debugging new failures.
Next module
With retrieval thoroughly covered, Module 5 moves to the next step in the pipeline: reranking and context building—taking retrieved candidates and preparing them for the LLM.