Diversity and deduplication
Avoid returning five near-identical chunks; increase coverage with diversification techniques.
When you retrieve the top-5 most similar chunks, they might all be saying essentially the same thing. If your chunking produced overlapping chunks, or if similar content exists in multiple documents, retrieval returns redundancy instead of coverage. This wastes context window space on repeated information and misses opportunities to provide the LLM with diverse perspectives on the topic.
The redundancy problem
Retrieval ranks by similarity, and similar chunks cluster together. If you have three chunks that cover the same concept with slightly different wording, all three will score highly for a query about that concept. You retrieve all three, pack them into context, and the LLM sees the same information three times while missing other relevant content that scored lower.
Overlap from chunking makes this worse. With 20% overlap, consecutive chunks share content. A query that matches the overlapping section retrieves both chunks—essentially the same information appears twice.
Document duplication compounds further. If the same FAQ exists in multiple places (the main FAQ page, a category-specific page, a help center landing page), each instance produces chunks that all match relevant queries.
The result is wasted context window on repetition and incomplete coverage of the topic.
Near-duplicate detection
The first step is identifying when chunks are near-duplicates rather than independently valuable.
Embedding similarity between retrieved chunks is a natural measure. If two chunks have similarity above 0.95 to each other, they're probably redundant. After retrieval, compute pairwise similarities and flag duplicates.
Text overlap using simpler measures (Jaccard similarity, longest common substring) can catch cases where chunks share text but embeddings differ slightly. If 80% of the words are the same, it's probably a duplicate.
Source deduplication uses metadata: if two chunks come from the same source document and adjacent positions, they're likely overlapping chunks rather than independent information. Keep one, drop the other.
The threshold for "duplicate" is a judgment call. Very high thresholds (0.99 similarity) catch only near-identical text; lower thresholds (0.85) catch paraphrases and rewrites. Start conservative and lower the threshold if redundancy persists.
Diversification strategies
Beyond removing exact duplicates, diversification actively seeks variety in retrieved results.
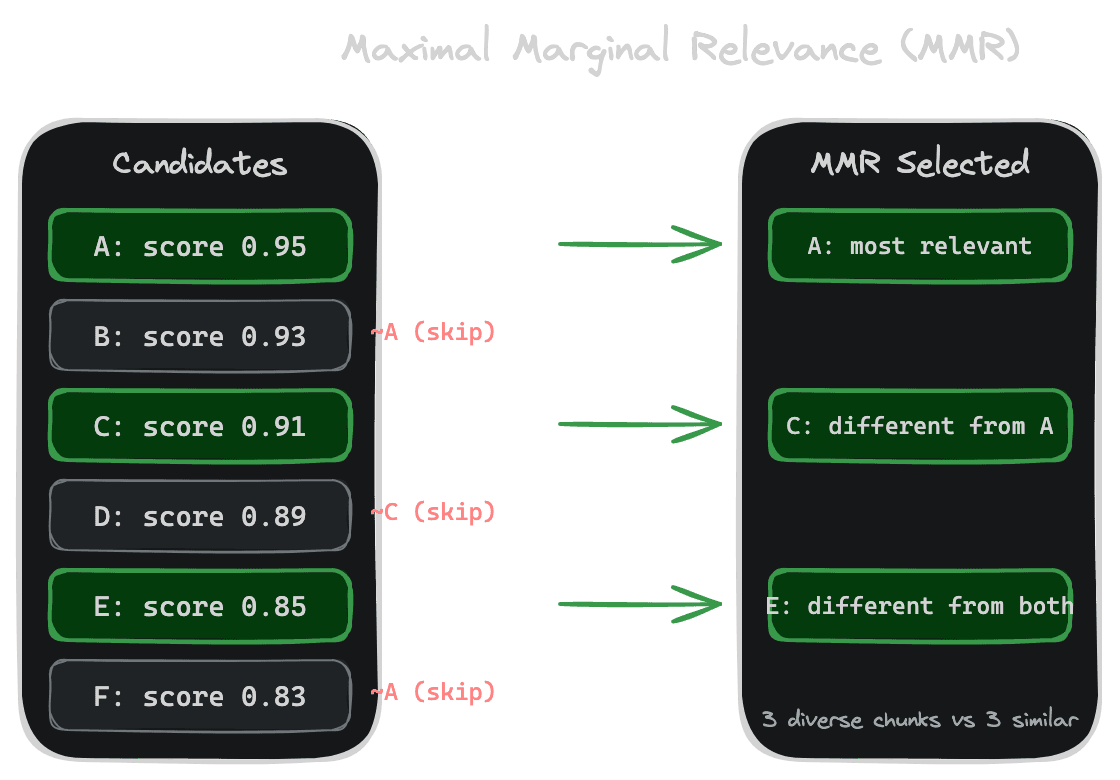
Maximal Marginal Relevance (MMR) is the classic approach. Instead of taking the top-K by similarity alone, MMR balances similarity to the query against dissimilarity to already-selected chunks. The formula trades off relevance and diversity with a tunable parameter. High diversity weighting produces varied results; low diversity weighting approaches pure similarity ranking.
MMR works by iteratively selecting chunks: pick the most relevant, then pick the most relevant-but-different from the first, then pick the most relevant-but-different from the first two, and so on. Each selection considers what's already included.
Clustering groups similar chunks, then selects representatives from each cluster. If 10 chunks form 3 clusters of similar content, select the top chunk from each cluster. This guarantees coverage across topics but requires clustering as a preprocessing step.
Source diversity limits how many chunks can come from one source document. "At most 2 chunks per document" ensures retrieval spans multiple documents rather than deeply exploring one. This works well when documents cover distinct aspects of a topic.
Aspect diversity is more sophisticated: identify aspects or subtopics in retrieved chunks (using an LLM or classifier) and ensure coverage across aspects. If a query about "authentication" retrieves chunks about login, permissions, tokens, and sessions, aspect diversity ensures all are represented rather than retrieving five chunks about login.
Implementation considerations
Diversification happens after initial retrieval, adding a post-processing step. The pattern is: retrieve top-50 candidates (more than you need), apply diversification to select top-5 for context, and proceed with the diversified set.
Retrieving extra candidates is important. If you retrieve exactly 5 and then deduplicate, you might end up with 3 after removing redundancy. Retrieve a larger pool so diversification has options to work with.
Diversification adds latency—computing pairwise similarities or running clustering takes time. For most applications the overhead is small (tens of milliseconds), but measure in your context.
Consider diversification strength carefully. Too aggressive and you lose highly relevant content in favor of variety; too weak and you still have redundancy. Tune based on evaluation results and user feedback.
One-per-document and similar rules
A simple heuristic that works surprisingly well is limiting results per source: "return at most one chunk from each document" or "return at most two chunks per source."
This doesn't require computing pairwise similarities or running clustering. It's just metadata-based filtering. If your sources are well-organized (each document covers a distinct topic or aspect), this rule naturally produces diverse results.
The limitation is that some queries are best served by multiple chunks from one document—a long document where several sections are relevant. Hard per-document limits might miss relevant content. Consider soft limits or query-dependent rules.
When not to diversify
Diversification assumes that more coverage is better than more depth. This isn't always true.
For queries seeking comprehensive information on a narrow topic, you might want multiple chunks from the same detailed document rather than brief mentions from several documents. Diversification would harm quality here.
For troubleshooting queries where the answer is specific and unambiguous, you want the most relevant content, period. Diversification might include tangentially related content that confuses rather than helps.
Consider query type when deciding whether to diversify. Some queries benefit from breadth; others benefit from depth. If you can classify queries, apply diversification selectively.
Next
With retrieval producing relevant, diverse results, the next chapter covers performance: caching, index tuning, and meeting latency requirements.