Query rewriting and decomposition
Improve recall by rewriting ambiguous queries and splitting multi-intent questions into sub-queries.
Users don't always phrase queries in ways that match how your content is written. They use different vocabulary, ask ambiguous questions, or combine multiple questions into one. Query rewriting transforms the user's input into forms more likely to retrieve relevant content. Decomposition breaks complex questions into simpler sub-queries that can be answered independently.
Why queries need transformation
The gap between how users ask and how content is written causes retrieval failures. A user asks "why is my thing not working" when the documentation says "troubleshooting authentication errors." A user asks "compare X and Y" when your content has separate pages for X and Y but nothing explicitly comparing them.
These aren't chunking problems or embedding problems—the query simply doesn't match the content well enough for similarity search to bridge the gap. Query transformation addresses this by modifying the query before retrieval.
Query rewriting patterns
Rewriting modifies the query to improve its chances of matching relevant content. Several patterns are common.
Expansion adds terms to the query to increase recall. If the user asks about "login problems," you might expand to "login authentication sign-in problems errors troubleshooting." This increases the chance of matching documents that use any of those terms. Expansion can be rule-based (synonym lists) or model-based (using an LLM to suggest related terms).
Reformulation rephrases the query to better match expected document language. An LLM can convert a casual question like "why can't I log in" to a more formal "causes of authentication failure" that might better match documentation style. This doesn't change the meaning, just the phrasing.
Disambiguation clarifies vague queries. If "billing" could refer to payment processing, invoice generation, or subscription management, disambiguation might ask the user which they mean—or generate multiple versions of the query to cover the possibilities.
Hypothetical document embedding (HyDE) generates a hypothetical answer to the query, then uses that answer's embedding for retrieval instead of the query's embedding. The intuition is that a hypothetical answer looks more like the actual documents than the question does. This works surprisingly well for some query types but adds latency and cost (it requires an LLM call before retrieval).
Implementing rewriting
The simplest approach uses an LLM to rewrite queries. You provide the original query with instructions like "Rewrite this question to be more specific and include relevant synonyms" and use the rewritten version for retrieval.
This adds latency (an LLM call before retrieval) and cost (tokens for every query). For high-volume applications, these costs matter. Consider caching rewrites for common queries, using a smaller/faster model for rewriting, or only rewriting queries that fail initial retrieval.
Rule-based expansion is cheaper: maintain a synonym dictionary and expand queries without LLM calls. This is less flexible but adds minimal latency. Hybrid approaches use rules for common cases and LLM for complex queries.
Query decomposition
Some queries are actually multiple questions combined. "What's the refund policy and how do I request one?" asks two things: policy details and process steps. If your documentation covers these in separate sections, a single retrieval might not find both.
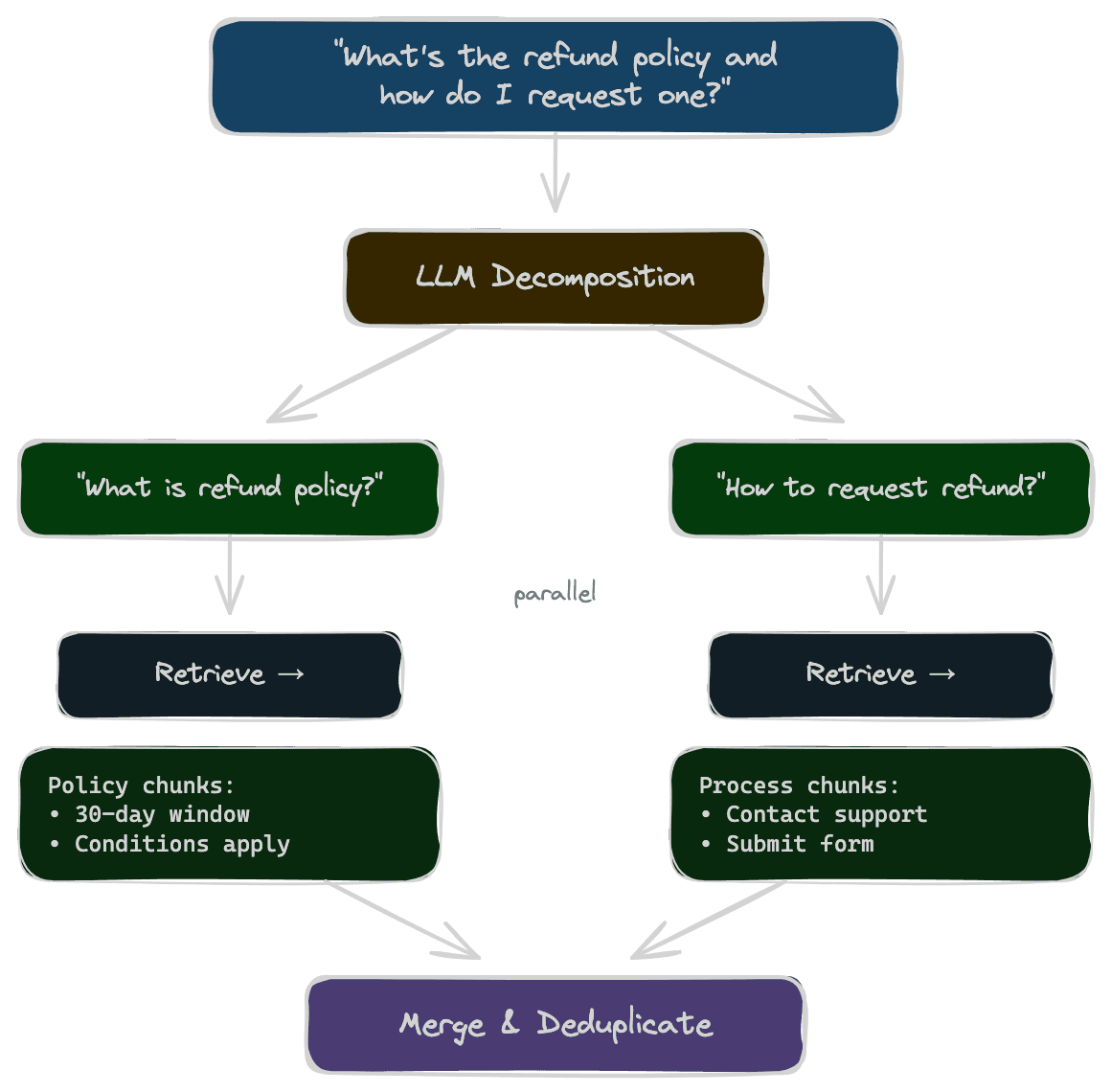
Decomposition splits the query into sub-queries, retrieves for each, and combines the results. The process: use an LLM to identify the distinct questions, retrieve relevant chunks for each sub-query, deduplicate and merge results, and pass the combined context to generation.
This increases recall for multi-part questions at the cost of more retrieval calls. The LLM decomposition step adds latency, but the sub-query retrievals can run in parallel.
Multi-hop questions
Some questions require synthesizing information from multiple sources. "What's the revenue of our biggest customer?" needs to first identify the biggest customer, then find their revenue. Retrieval for the original question won't find either piece directly.
Multi-hop retrieval is a form of decomposition where later queries depend on earlier results. You retrieve to answer "who is our biggest customer," extract that answer, then retrieve again for "[customer name] revenue."
This is more complex than simple decomposition because queries are sequential rather than parallel, and errors compound—if the first step fails, the second will too. Multi-hop is powerful for complex questions but requires careful implementation and error handling.
Risks of query transformation
Transformation isn't free, and it introduces risks.
Drift from user intent: Aggressive rewriting can change what the user is actually asking. If the user asks about "billing issues" and you rewrite to "payment processing errors," you might retrieve content about payment processing that doesn't address their actual billing concern.
Latency: Every LLM call adds time. For interactive applications, adding 500ms for query rewriting might be unacceptable. Measure the quality improvement against the latency cost.
Cost: LLM calls cost money. If you're processing millions of queries, rewriting every one adds up. Consider only rewriting queries that seem likely to benefit (short queries, ambiguous queries, queries that failed initial retrieval).
Security surface: If your rewriting prompt includes the user's query, you're exposing the LLM to potential prompt injection. A malicious query could attempt to manipulate the rewriting process. Treat user input as untrusted, even in internal processing steps.
Debugging complexity: When retrieval fails after transformation, you need to know whether the original query was the problem or the transformation introduced an issue. Log both original and transformed queries to enable debugging.
When to use transformation
Query transformation is most valuable when there's a systematic mismatch between query language and content language, when users frequently ask ambiguous or multi-part questions, when simpler improvements (better chunking, better embeddings) have been exhausted, and when the latency and cost are acceptable for your use case.
Start without transformation. Measure retrieval quality with baseline queries. Identify specific failure patterns that transformation could address. Implement targeted transformations for those patterns rather than transforming every query.
Next
Query transformation improves individual query quality. The next chapter covers routing—directing queries to the right index or corpus to improve results and efficiency.