Cost controls and model routing
Control spend with caps, caching, adaptive retrieval, and model routing based on query class.
RAG systems cost money. Every query embeds, retrieves, maybe reranks, and generates. Each of these stages has a price: embedding tokens, vector database queries, reranker inference, and LLM generation tokens. At small scale, costs are negligible. At production scale, they compound quickly. Understanding where costs come from and how to control them is essential for sustainable operations.
Cost optimization isn't about making everything as cheap as possible—that sacrifices quality. It's about spending efficiently: paying for quality where it matters and reducing cost where it doesn't. This requires knowing which queries are expensive, which are cheap, and routing them appropriately.
Where the cost comes from
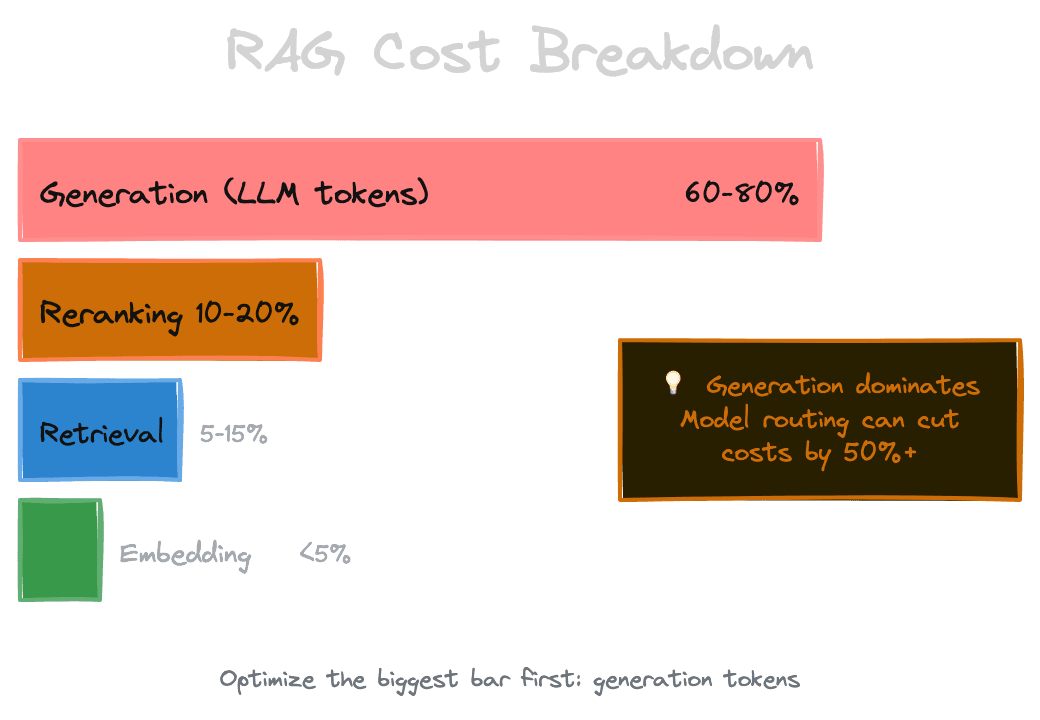
Break down your per-query cost into its components.
Embedding costs are usually low. Embedding models are relatively cheap, and you're embedding a short query (tens to hundreds of tokens). At scale, embedding costs might be $0.0001 per query or less. However, embedding during ingestion is a bigger cost—you embed every document once, and for large corpora this adds up.
Retrieval costs depend on your vector database. Managed services charge per query, per storage, or per compute time. Self-hosted solutions have infrastructure costs. Retrieval is typically cheap per query but scales with corpus size (larger indexes may require more compute) and query volume.
Reranking costs can be significant. Reranker models process each candidate passage with the query, so cost scales with the number of candidates. If you rerank 50 candidates per query using a hosted reranker, this can be more expensive than retrieval.
Generation is usually the dominant cost. LLM inference is priced by tokens, and you're sending context (potentially thousands of tokens) plus generating a response (hundreds of tokens). A single query might cost $0.01-0.05 or more with large context windows and premium models. Multiply by thousands of daily queries and this becomes real money.
Cost monitoring and attribution
You can't control what you don't measure. Instrument your pipeline to track costs per query and attribute them to stages.
Build dashboards that show daily/weekly cost by stage. Track cost per query distributions—the mean is less important than the tail. A few expensive queries might dominate your bill. Identify what makes queries expensive: long context, complex questions requiring multiple retrievals, high rerank candidate counts.
Attribution helps you optimize. If 80% of your cost is generation and only 5% is reranking, optimizing reranking won't move the needle. If a small fraction of queries consume a disproportionate share of cost, those are candidates for special handling.
Caching for cost reduction
Caching reduces costs by avoiding redundant computation.
Embedding caches save embedding costs for repeated queries. Exact match caches are cheap and effective. Semantic caches (matching similar queries by embedding similarity) can provide higher hit rates but require more infrastructure.
Retrieval caches save database query costs. If the same query with the same filters was recently executed, return the cached result. This is effective when you have repeated or clustered queries.
Response caches save generation costs—the biggest win. If the exact same question with the exact same context was recently answered, return the cached response. The challenge is that contexts often differ slightly, reducing cache hit rates. Consider hashing the context to enable matching.
Semantic response caching goes further: if a new query is semantically similar to a cached query and the corpus hasn't changed, you might be able to return the cached response. This is aggressive but can dramatically reduce generation costs for repetitive workloads.
Adaptive retrieval depth
Not every query needs the same retrieval depth. Simple factual questions might be answerable from the top result. Complex analytical questions might need many sources.
Adaptive topK adjusts how many candidates you retrieve based on query characteristics. A classifier or heuristic might predict that "what is your refund policy?" needs only topK=3, while "compare all the pricing tiers" needs topK=20.
Conditional reranking runs the reranker only when retrieval confidence is uncertain. If the top result has very high similarity and the second result is much lower, the ranking is probably stable—skip reranking. If the top-5 are all clustered with similar scores, reranking might change the order significantly—it's worth the cost.
Early stopping in reranking can also save cost. If the reranker produces highly confident scores for the top few candidates, you might not need to score all 50. This requires reranker-specific support but can significantly reduce inference.
Model routing by query complexity
The most powerful cost lever is routing queries to appropriate models. Not every query needs GPT-4. Many can be handled by smaller, cheaper models.
Build a router that classifies queries by complexity. Simple factual queries, FAQ-style questions, and short-answer requests might route to a smaller model. Complex reasoning, synthesis across sources, or nuanced questions route to a more capable model.
The router can be a classifier trained on your traffic, a heuristic based on query length and terminology, or even a lightweight LLM call that assesses complexity (though this adds latency and cost, so it only makes sense at high scale).
Model routing can reduce generation costs by 10x or more for suitable workloads. If 60% of queries are simple and can use a model that's 10x cheaper, you've cut generation cost by over 50% without sacrificing quality on complex queries.
Context length management
Generation cost scales with context tokens. Sending 10,000 tokens of context costs more than sending 2,000 tokens.
The context compression techniques from Module 5 (extractive and abstractive compression) reduce cost by reducing context size. A 60% compression ratio means 60% lower context costs.
Also reconsider how much context you actually need. Many systems default to filling the context window because they can. But more context isn't always better—it can confuse models, dilute relevant information, and increase cost. Experiment with smaller context budgets and measure whether quality actually suffers.
Spend caps and circuit breakers
Set spend limits to avoid surprises. Many LLM providers support usage caps. Even if they don't, build your own.
Track cumulative spend per time period (daily, weekly). When approaching a threshold, take action: enable aggressive caching, route more queries to cheaper models, or in extreme cases, temporarily reduce service (return cached or simplified responses, or queue non-urgent queries).
Circuit breakers can pause expensive operations during cost spikes. If generation cost suddenly doubles (perhaps due to a traffic surge or an attack), the circuit breaker can throttle queries, inject delays, or switch to a cheaper model until the situation stabilizes.
Optimizing ingestion cost
Query-time cost gets attention, but ingestion cost matters too—especially for large or frequently updated corpora.
Embedding during ingestion is a major cost for large document sets. Batch embeddings to reduce per-request overhead. Use cheaper embedding models if ingestion quality isn't as critical (though this often isn't advisable since retrieval quality depends on embedding quality).
Incremental indexing reduces re-embedding cost. When a document is updated, only re-embed changed chunks, not the entire document. When the corpus is refreshed, compute deltas and only process new or modified content.
If you're re-indexing frequently (for freshness), consider the cost tradeoff. Daily re-indexing of a million-document corpus is expensive. Maybe weekly or incremental is sufficient for your use case.
Next
With cost under control, the next chapter covers a different kind of risk: security. RAG systems face unique vulnerabilities, especially prompt injection through retrieved content.