Governance, privacy, and compliance
Retention, deletion guarantees, audit trails, and privacy constraints that RAG systems must respect.
RAG systems don't operate in a vacuum. They exist within organizations that have policies about data retention, privacy regulations they must comply with, and audit requirements they must satisfy. What makes RAG challenging for governance is that it creates new data artifacts—embeddings, chunks, retrieval logs—that traditional policies might not address. And it enables new access patterns that can bypass traditional controls.
This chapter covers the governance considerations that production RAG systems face. The specifics vary enormously by jurisdiction, industry, and organization, so we'll focus on the categories of concerns and general approaches rather than prescribing specific solutions.
Data lifecycle in RAG
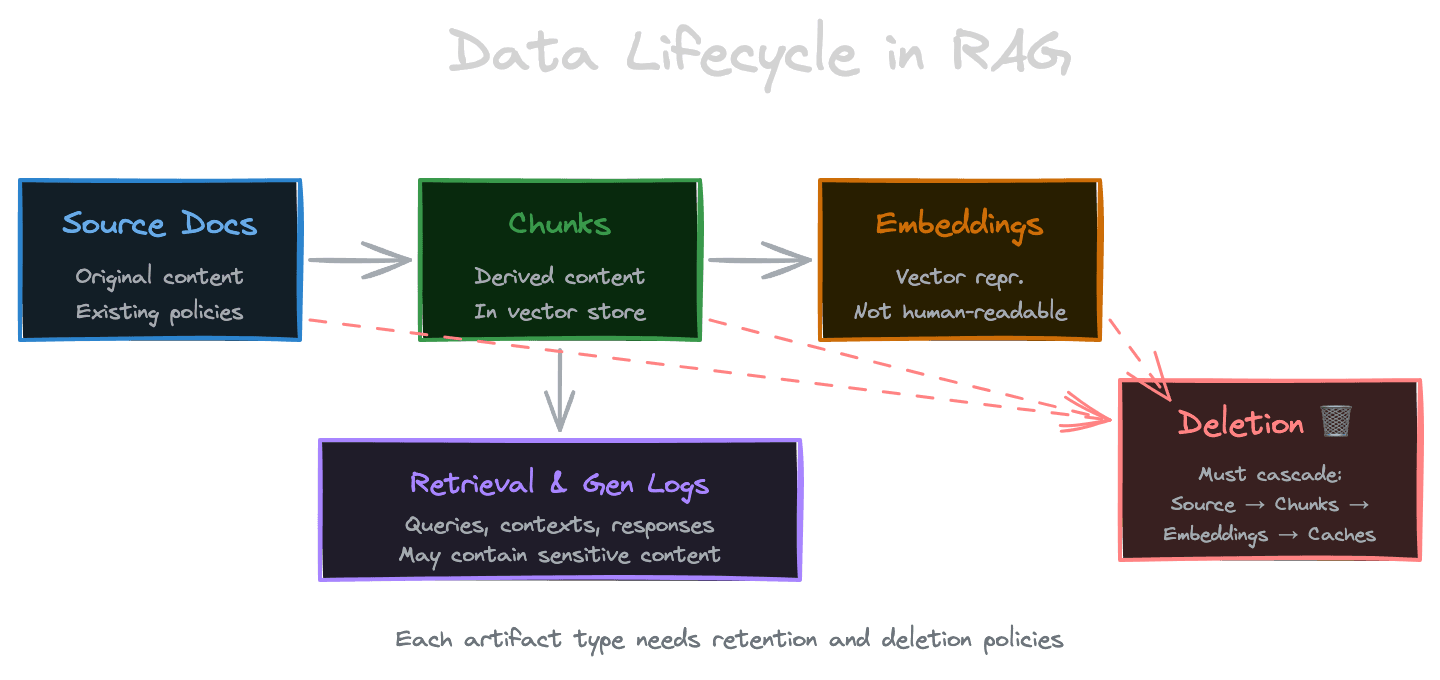
RAG creates multiple representations of your data, each with its own lifecycle.
Source documents are your original content. These likely have existing retention and deletion policies. But ingestion into RAG doesn't change them; it creates derived data.
Chunks are derived from source documents during ingestion. They're stored alongside embeddings in your vector store. When a source document is deleted, should its chunks be deleted? Usually yes, but you need to track the relationship and implement the deletion.
Embeddings are mathematical representations of chunks. They're not human-readable but can potentially reconstruct some information about the original text. Deleting chunks should delete their embeddings.
Retrieval logs record which documents were retrieved for which queries. These are useful for debugging and analytics but can reveal sensitive information about what users are asking and what documents they're accessing.
Generation logs record prompts and responses. These might contain the actual content of chunks, user queries, and LLM outputs—potentially sensitive across all three.
For each artifact type, define retention policies, deletion procedures, and access controls.
Right to deletion and erasure
Regulations like GDPR grant individuals the right to have their data deleted. In RAG, this is more complex than deleting a database row.
If personal data appears in documents that were ingested, deletion means removing those documents from the corpus, deleting their chunks from the vector store, and ensuring the embeddings are removed. Vector stores vary in their deletion capabilities—some make deletion easy, others less so.
Deletion should be cascading. When a source document is deleted, automatically delete all derived chunks and embeddings. Track the lineage: you need to know which chunk IDs came from which document.
Consider whether deletion needs to extend to caches. If retrieval results are cached and a document is deleted, stale cache entries might continue returning the deleted content. Cache invalidation should be tied to document deletion.
Also consider generation logs. If a deleted document's content was included in a past prompt or response, should those logs be purged? This is a policy decision, but awareness is the first step.
Audit trails and provenance
For regulated industries, you may need to prove what the system did and why.
Retrieval audit trails record which documents were retrieved for each query. This supports questions like "who accessed this document through the RAG system?" and "what documents informed this answer?"
Generation audit trails record prompts and responses. For compliance-sensitive outputs, you might need to retain the exact context that produced a specific answer, enabling recreation and review.
Access audit trails record which users queried the system and what permissions they had. This integrates with your broader access logging but should specifically capture RAG interactions.
Design audit logs for queryability. You might need to answer "show me every query that retrieved document X" or "what queries did user Y make involving topic Z?" Structure your logs to support these queries.
Retention of audit logs is its own policy question. Logs useful for debugging might only need short retention. Logs required for compliance might need years of retention.
Access control and permissions
RAG can inadvertently bypass access controls if not carefully designed.
Consider a document that only executives should see. Traditional access control prevents regular employees from opening the document. But if RAG ingests the document and retrieves chunks from it for any user's query, the content leaks. The LLM might summarize or quote the restricted content in its response.
The solution is applying access control at retrieval time, not just at document access time. Filters should exclude documents the querying user isn't authorized to see. This requires integrating your permission model with your retrieval system.
Implementation varies. You might store permission metadata with each chunk and filter at query time. You might maintain separate indexes for different access levels. You might call your permission system during retrieval to filter results.
The key point is that RAG doesn't automatically inherit the access controls of your source systems. You must implement equivalent controls in your RAG layer.
Privacy considerations
Beyond explicit access controls, consider privacy implications of RAG.
Query privacy: User queries might reveal sensitive information—health concerns, legal issues, financial problems. Treat query logs with appropriate care. Consider whether queries need to be logged with user identifiers or can be anonymized.
Inference privacy: Even if a user can't directly access a document, RAG might enable inference attacks. By crafting queries, an attacker might piece together information from partial matches across authorized documents. This is subtle and hard to prevent completely, but awareness helps.
Model privacy: If you're using external LLM APIs, you're sending your documents' content to a third party. This might violate confidentiality policies or regulations. Consider self-hosted models or providers with strong data protection guarantees for sensitive content.
Embedding privacy: Embeddings encode information about the original text. Research has shown that text can sometimes be reconstructed from embeddings. Treat embeddings as sensitive data, not as safe anonymizations.
Content classification
Not all content should be treated equally. Classify content by sensitivity and apply appropriate controls.
Public documentation might be ingested freely with minimal restrictions. Internal documentation might require user authentication. Confidential content might require specific role permissions. Highly restricted content might be excluded from RAG entirely.
Apply the classification at ingestion time, storing sensitivity labels with chunks. Use these labels to enforce access control and to make decisions about caching, logging, and retention.
Consider whether classification should be automated or manual. Automated classification can scan for patterns (credit card numbers, health information, legal terms) but will have false positives and negatives. Manual classification is more accurate but doesn't scale. Hybrid approaches—automated with human review for borderline cases—balance accuracy and efficiency.
Compliance frameworks
Various compliance frameworks have implications for RAG.
GDPR (General Data Protection Regulation) affects any system processing EU residents' data. Key implications: purpose limitation (are you using data only for its intended purpose?), data minimization (are you processing only what's necessary?), deletion rights (can you honor erasure requests?), and transparency (do users know their data is processed by RAG?).
HIPAA (Health Insurance Portability and Accountability Act) affects health data in the US. If your RAG system processes patient information, you need appropriate safeguards, access controls, and audit trails.
SOC 2 is an audit standard for service organizations. RAG systems in scope need documented security controls, access management, and monitoring.
Industry-specific regulations (financial services, legal, government) add further requirements. The common threads are: know what data you have, control who can access it, be able to demonstrate compliance through logs and audits.
Vendor and third-party considerations
Many RAG systems rely on third-party services: embedding APIs, vector databases, LLM providers.
Evaluate the compliance posture of your vendors. Do they have relevant certifications? What are their data handling practices? Are they willing to sign data processing agreements?
Understand data flows. When you send a query to an embedding API, is the text logged? Retained? Used for training? For sensitive applications, you may need contractual guarantees or self-hosted alternatives.
Geographic considerations apply too. Some regulations restrict data from crossing borders. Using a US-based LLM provider for EU personal data might be problematic. Check where your vendors process data and whether that's acceptable for your regulatory environment.
Next
The final chapter of this module covers scaling—how to grow your RAG system from single-tenant prototype to large-scale multi-tenant production deployment.